13 KiB
| stage | group | info |
|---|---|---|
| Verify | Pipeline Execution | To determine the technical writer assigned to the Stage/Group associated with this page, see https://about.gitlab.com/handbook/product/ux/technical-writing/#assignments |
Jobs (FREE)
Pipeline configuration begins with jobs. Jobs are the most fundamental element of a .gitlab-ci.yml file.
Jobs are:
- Defined with constraints stating under what conditions they should be executed.
- Top-level elements with an arbitrary name and must contain at least the
scriptclause. - Not limited in how many can be defined.
For example:
job1:
script: "execute-script-for-job1"
job2:
script: "execute-script-for-job2"
The above example is the simplest possible CI/CD configuration with two separate
jobs, where each of the jobs executes a different command.
Of course a command can execute code directly (./configure;make;make install)
or run a script (test.sh) in the repository.
Jobs are picked up by runners and executed in the environment of the runner. What is important is that each job is run independently from each other.
View jobs in a pipeline
When you access a pipeline, you can see the related jobs for that pipeline.
Selecting an individual job shows you its job log, and allows you to:
- Cancel the job.
- Retry the job.
- Erase the job log.
View all jobs in a project
To view the full list of jobs that ran in a project:
- On the top bar, select Main menu > Projects and find the project.
- On the left sidebar, select CI/CD > Jobs.
You can filter the list by job status.
See why a job failed
When a pipeline fails or is allowed to fail, there are several places where you can find the reason:
- In the pipeline graph, on the pipeline detail view.
- In the pipeline widgets, in the merge requests and commit pages.
- In the job views, in the global and detailed views of a job.
In each place, if you hover over the failed job you can see the reason it failed.
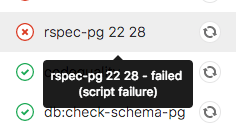
You can also see the reason it failed on the Job detail page.
The order of jobs in a pipeline
The order of jobs in a pipeline depends on the type of pipeline graph.
- For full pipeline graphs, jobs are sorted by name.
- For pipeline mini graphs, jobs are sorted by status, and then by name.
The job status order is:
- failed
- warning
- pending
- running
- manual
- scheduled
- canceled
- success
- skipped
- created
For example:

Job name limitations
- Enabled 255-character job length on GitLab.com in GitLab 14.5.
- Generally available in GitLab 14.10. Feature flag
ci_validate_job_lengthremoved.
You can't use these keywords as job names:
imageservicesstagestypesbefore_scriptafter_scriptvariablescacheincludetruefalsenilpages:deployconfigured for adeploystage
Job names must be 255 characters or fewer.
Use unique names for your jobs. If multiple jobs have the same name in a file, only one is added to the pipeline, and it's difficult to predict which one is chosen. If the same job name is used in one or more included files, parameters are merged.
Group jobs in a pipeline
If you have many similar jobs, your pipeline graph becomes long and hard to read.
You can automatically group similar jobs together. If the job names are formatted in a certain way, they are collapsed into a single group in regular pipeline graphs (not the mini graphs).
You can recognize when a pipeline has grouped jobs if you don't see the retry or cancel button inside them. Hovering over them shows the number of grouped jobs. Select to expand them.

To create a group of jobs, in the CI/CD pipeline configuration file, separate each job name with a number and one of the following:
- A slash (
/), for example,slash-test 1/3,slash-test 2/3,slash-test 3/3. - A colon (
:), for example,colon-test 1:3,colon-test 2:3,colon-test 3:3. - A space, for example
space-test 0 3,space-test 1 3,space-test 2 3.
You can use these symbols interchangeably.
In the example below, these three jobs are in a group named build ruby:
build ruby 1/3:
stage: build
script:
- echo "ruby1"
build ruby 2/3:
stage: build
script:
- echo "ruby2"
build ruby 3/3:
stage: build
script:
- echo "ruby3"
The pipeline graph displays a group named build ruby with three jobs.
The jobs are ordered by comparing the numbers from left to right. You usually want the first number to be the index and the second number to be the total.
This regular expression
evaluates the job names: ([\b\s:]+((\[.*\])|(\d+[\s:\/\\]+\d+))){1,3}\s*\z.
One or more : [...], X Y, X/Y, or X\Y sequences are removed from the end
of job names only. Matching substrings found at the beginning or in the middle of
job names are not removed.
In GitLab 13.8 and earlier,
the regular expression is \d+[\s:\/\\]+\d+\s*. Feature flag
removed in GitLab 13.11.
Hide jobs
To temporarily disable a job without deleting it from the configuration file:
-
Comment out the job's configuration:
# hidden_job: # script: # - run test -
Start the job name with a dot (
.) and it is not processed by GitLab CI/CD:.hidden_job: script: - run test
You can use hidden jobs that start with . as templates for reusable configuration with:
- The
extendskeyword. - YAML anchors.
Control the inheritance of default keywords and global variables
You can control the inheritance of:
For example:
default:
image: 'ruby:2.4'
before_script:
- echo Hello World
variables:
DOMAIN: example.com
WEBHOOK_URL: https://my-webhook.example.com
rubocop:
inherit:
default: false
variables: false
script: bundle exec rubocop
rspec:
inherit:
default: [image]
variables: [WEBHOOK_URL]
script: bundle exec rspec
capybara:
inherit:
variables: false
script: bundle exec capybara
karma:
inherit:
default: true
variables: [DOMAIN]
script: karma
In this example:
rubocop:- inherits: Nothing.
rspec:- inherits: the default
imageand theWEBHOOK_URLvariable. - does not inherit: the default
before_scriptand theDOMAINvariable.
- inherits: the default
capybara:- inherits: the default
before_scriptandimage. - does not inherit: the
DOMAINandWEBHOOK_URLvariables.
- inherits: the default
karma:- inherits: the default
imageandbefore_script, and theDOMAINvariable. - does not inherit:
WEBHOOK_URLvariable.
- inherits: the default
Specifying variables when running manual jobs
Introduced in GitLab 12.2.
When running manual jobs you can supply additional job specific variables.
You can do this from the job page of the manual job you want to run with additional variables. To access this page, select the name of the manual job in the pipeline view, not the play ({play}) button.
Define CI/CD variables here when you want to alter the execution of a job that uses
CI/CD variables.
Add a variable name (key) and value to override the value
defined in the UI or .gitlab-ci.yml
for a single run of the manual job.

Delay a job
When you do not want to run a job immediately, you can use the when:delayed keyword to
delay a job's execution for a certain period.
This is especially useful for timed incremental rollout where new code is rolled out gradually.
For example, if you start rolling out new code and:
- Users do not experience trouble, GitLab can automatically complete the deployment from 0% to 100%.
- Users experience trouble with the new code, you can stop the timed incremental rollout by canceling the pipeline and rolling back to the last stable version.

Expand and collapse job log sections
Introduced in GitLab 12.0.
Job logs are divided into sections that can be collapsed or expanded. Each section displays the duration.
In the following example:
- Three sections are collapsed and can be expanded.
- Three sections are expanded and can be collapsed.
Custom collapsible sections
Introduced in GitLab 12.0.
You can create collapsible sections in job logs by manually outputting special codes that GitLab uses to determine what sections to collapse:
- Section start marker:
\e[0Ksection_start:UNIX_TIMESTAMP:SECTION_NAME\r\e[0K+TEXT_OF_SECTION_HEADER - Section end marker:
\e[0Ksection_end:UNIX_TIMESTAMP:SECTION_NAME\r\e[0K
You must add these codes to the script section of the CI configuration. For example,
using echo:
job1:
script:
- echo -e "\e[0Ksection_start:`date +%s`:my_first_section\r\e[0KHeader of the 1st collapsible section"
- echo 'this line should be hidden when collapsed'
- echo -e "\e[0Ksection_end:`date +%s`:my_first_section\r\e[0K"
Depending on the shell that your runner uses, for example if it is using Zsh, you may need to
escape the special characters like so: \\e and \\r.
In the example above:
date +%s: The Unix timestamp (for example1560896352).my_first_section: The name given to the section.\r\e[0K: Prevents the section markers from displaying in the rendered (colored) job log, but they are displayed in the raw job log. To see them, in the top right of the job log, select {doc-text} (Show complete raw).\r: carriage return.\e[0K: clear line ANSI escape code.
Sample raw job log:
\e[0Ksection_start:1560896352:my_first_section\r\e[0KHeader of the 1st collapsible section
this line should be hidden when collapsed
\e[0Ksection_end:1560896353:my_first_section\r\e[0K
Pre-collapse sections
Introduced in GitLab 13.5.
You can make the job log automatically collapse collapsible sections by adding the collapsed option to the section start.
Add [collapsed=true] after the section name and before the \r. The section end marker
remains unchanged:
- Section start marker with
[collapsed=true]:\e[0Ksection_start:UNIX_TIMESTAMP:SECTION_NAME[collapsed=true]\r\e[0K+TEXT_OF_SECTION_HEADER - Section end marker:
\e[0Ksection_end:UNIX_TIMESTAMP:SECTION_NAME\r\e[0K
Add the updated section start text to the CI configuration. For example,
using echo:
job1:
script:
- echo -e "\e[0Ksection_start:`date +%s`:my_first_section[collapsed=true]\r\e[0KHeader of the 1st collapsible section"
- echo 'this line should be hidden automatically after loading the job log'
- echo -e "\e[0Ksection_end:`date +%s`:my_first_section\r\e[0K"
Deployment jobs
Deployment jobs are a specific kind of CI job in that they deploy code to
environments. A deployment job is any job that
uses the environment keyword and the start environment action.
Deployment jobs do not need to be in the deploy stage. The following deploy me
job is an example of a deployment job. action: start is the default behavior and
is defined for the sake of the example, but you can omit it:
deploy me:
script:
- deploy-to-cats.sh
environment:
name: production
url: https://cats.example.com
action: start
The behavior of deployment jobs can be controlled with deployment safety settings like preventing outdated deployment jobs and ensuring only one deployment job runs at a time.