14 KiB
Extra Sidekiq processes (STARTER ONLY)
NOTE: Note: The information in this page applies only to Omnibus GitLab.
GitLab Starter allows one to start an extra set of Sidekiq processes besides the default one. These processes can be used to consume a dedicated set of queues. This can be used to ensure certain queues always have dedicated workers, no matter the number of jobs that need to be processed.
Available Sidekiq queues
For a list of the existing Sidekiq queues, check the following files:
Each entry in the above files represents a queue on which extra Sidekiq processes can be started.
Starting extra processes
To start extra Sidekiq processes, you must enable sidekiq-cluster:
-
Edit
/etc/gitlab/gitlab.rband add:sidekiq_cluster['enable'] = true -
You will then need to specify how many additional processes to create via
sidekiq-clusterand which queue they should handle via thesidekiq_cluster['queue_groups']array setting. Each item in the array equates to one additional Sidekiq process, and values in each item determine the queues it works on.For example, the following setting adds additional Sidekiq processes to two queues, one to
elastic_indexerand one tomailers:sidekiq_cluster['queue_groups'] = [ "elastic_indexer", "mailers" ]To have an additional Sidekiq process handle multiple queues, add multiple queue names to its item delimited by commas. For example:
sidekiq_cluster['queue_groups'] = [ "elastic_indexer, elastic_commit_indexer", "mailers" ]In GitLab 12.9 and later, the special queue name
*means all queues. This starts two processes, each handling all queues:sidekiq_cluster['queue_groups'] = [ "*", "*" ]*cannot be combined with concrete queue names -*, mailerswill just handle themailersqueue. -
Save the file and reconfigure GitLab for the changes to take effect:
sudo gitlab-ctl reconfigure
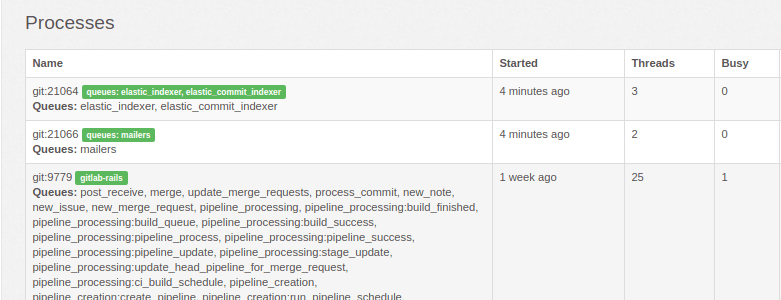
Once the extra Sidekiq processes are added, you can visit the
Admin Area > Monitoring > Background Jobs (/admin/background_jobs) in GitLab.
Negating settings
To have the additional Sidekiq processes work on every queue except the ones you list:
-
After you follow the steps for starting extra processes, edit
/etc/gitlab/gitlab.rband add:sidekiq_cluster['negate'] = true -
Save the file and reconfigure GitLab for the changes to take effect:
sudo gitlab-ctl reconfigure
Queue selector (experimental)
Introduced in GitLab Starter 12.8.
CAUTION: Caution: As this is marked as experimental, it is subject to change at any time, including breaking backwards compatibility. This is so that we can react to changes we need for our GitLab.com deployment. We have a tracking issue open to remove the experimental designation from this feature; please comment there if you are interested in using this in your own deployment.
In addition to selecting queues by name, as above, the
experimental_queue_selector option allows queue groups to be selected
in a more general way using the following components:
- Attributes that can be selected.
- Operators used to construct a query.
Available attributes
From the list of all available
attributes,
experimental_queue_selector allows selecting of queues by the
following attributes:
feature_category- the GitLab feature category the queue belongs to. For example, themergequeue belongs to thesource_code_managementcategory.has_external_dependencies- whether or not the queue connects to external services. For example, all importers have this set totrue.urgency- how important it is that this queue's jobs run quickly. Can behigh,low, orthrottled. For example, theauthorized_projectsqueue is used to refresh user permissions, and is high urgency.name- the queue name. The other attributes are typically more useful as they are more general, but this is available in case a particular queue needs to be selected.resource_boundary- if the worker is bound bycpu,memory, orunknown. For example, theproject_exportqueue is memory bound as it has to load data in memory before saving it for export.
has_external_dependencies is a boolean attribute: only the exact
string true is considered true, and everything else is considered
false.
Available operators
experimental_queue_selector supports the following operators, listed
from highest to lowest precedence:
|- the logical OR operator. For example,query_a|query_b(wherequery_aandquery_bare queries made up of the other operators here) will include queues that match either query.&- the logical AND operator. For example,query_a&query_b(wherequery_aandquery_bare queries made up of the other operators here) will only include queues that match both queries.!=- the NOT IN operator. For example,feature_category!=issue_trackingexcludes all queues from theissue_trackingfeature category.=- the IN operator. For example,resource_boundary=cpuincludes all queues that are CPU bound.,- the concatenate set operator. For example,feature_category=continuous_integration,pagesincludes all queues from either thecontinuous_integrationcategory or thepagescategory. This example is also possible using the OR operator, but allows greater brevity, as well as being lower precedence.
The operator precedence for this syntax is fixed: it's not possible to make AND have higher precedence than OR.
In GitLab 12.9 and
later, as with the standard queue group syntax above, a single * as the
entire queue group selects all queues.
Example queries
In /etc/gitlab/gitlab.rb:
sidekiq_cluster['enable'] = true
sidekiq_cluster['experimental_queue_selector'] = true
sidekiq_cluster['queue_groups'] = [
# Run all non-CPU-bound queues that are high urgency
'resource_boundary!=cpu&urgency=high',
# Run all continuous integration and pages queues that are not high urgency
'feature_category=continuous_integration,pages&urgency!=high',
# Run all queues
'*'
]
Ignore all GitHub import queues
When importing from GitHub, Sidekiq might
use all of its resources to perform those operations. To set up a separate
sidekiq-cluster process to ignore all GitHub import-related queues:
-
Edit
/etc/gitlab/gitlab.rband add:sidekiq_cluster['enable'] = true sidekiq_cluster['negate'] = true sidekiq_cluster['queue_groups'] = [ "github_import_advance_stage", "github_importer:github_import_import_diff_note", "github_importer:github_import_import_issue", "github_importer:github_import_import_note", "github_importer:github_import_import_lfs_object", "github_importer:github_import_import_pull_request", "github_importer:github_import_refresh_import_jid", "github_importer:github_import_stage_finish_import", "github_importer:github_import_stage_import_base_data", "github_importer:github_import_stage_import_issues_and_diff_notes", "github_importer:github_import_stage_import_notes", "github_importer:github_import_stage_import_lfs_objects", "github_importer:github_import_stage_import_pull_requests", "github_importer:github_import_stage_import_repository" ] -
Save the file and reconfigure GitLab for the changes to take effect:
sudo gitlab-ctl reconfigure
Number of threads
Each process defined under sidekiq_cluster starts with a
number of threads that equals the number of queues, plus one spare thread.
For example, a process that handles the process_commit and post_receive
queues will use three threads in total.
Managing concurrency
When setting the maximum concurrency, keep in mind this normally should not exceed the number of CPU cores available. The values in the examples below are arbitrary and not particular recommendations.
Each thread requires a Redis connection, so adding threads may increase Redis latency and potentially cause client timeouts. See the Sidekiq documentation about Redis for more details.
When running a single Sidekiq process (default)
-
Edit
/etc/gitlab/gitlab.rband add:sidekiq['concurrency'] = 25 -
Save the file and reconfigure GitLab for the changes to take effect:
sudo gitlab-ctl reconfigure
This will set the concurrency (number of threads) for the Sidekiq process.
When running Sidekiq cluster
-
Edit
/etc/gitlab/gitlab.rband add:sidekiq_cluster['min_concurrency'] = 15 sidekiq_cluster['max_concurrency'] = 25 -
Save the file and reconfigure GitLab for the changes to take effect:
sudo gitlab-ctl reconfigure
min_concurrency and max_concurrency are independent; one can be set without
the other. Setting min_concurrency to 0 will disable the limit.
For each queue group, let N be one more than the number of queues. The concurrency factor will be set to:
N, if it's betweenmin_concurrencyandmax_concurrency.max_concurrency, ifNexceeds this value.min_concurrency, ifNis less than this value.
If min_concurrency is equal to max_concurrency, then this value will be used
regardless of the number of queues.
When min_concurrency is greater than max_concurrency, it is treated as
being equal to max_concurrency.
Modifying the check interval
To modify the check interval for the additional Sidekiq processes:
-
Edit
/etc/gitlab/gitlab.rband add:sidekiq_cluster['interval'] = 5 -
Save the file and reconfigure GitLab for the changes to take effect.
This tells the additional processes how often to check for enqueued jobs.
Troubleshooting using the CLI
CAUTION: Warning:
It's recommended to use /etc/gitlab/gitlab.rb to configure the Sidekiq processes.
If you experience a problem, you should contact GitLab support. Use the command
line at your own risk.
For debugging purposes, you can start extra Sidekiq processes by using the command
/opt/gitlab/embedded/service/gitlab-rails/bin/sidekiq-cluster. This command
takes arguments using the following syntax:
/opt/gitlab/embedded/service/gitlab-rails/bin/sidekiq-cluster [QUEUE,QUEUE,...] [QUEUE, ...]
Each separate argument denotes a group of queues that have to be processed by a Sidekiq process. Multiple queues can be processed by the same process by separating them with a comma instead of a space.
Instead of a queue, a queue namespace can also be provided, to have the process automatically listen on all queues in that namespace without needing to explicitly list all the queue names. For more information about queue namespaces, see the relevant section in the Sidekiq style guide.
For example, say you want to start 2 extra processes: one to process the
process_commit queue, and one to process the post_receive queue. This can be
done as follows:
/opt/gitlab/embedded/service/gitlab-rails/bin/sidekiq-cluster process_commit post_receive
If you instead want to start one process processing both queues, you'd use the following syntax:
/opt/gitlab/embedded/service/gitlab-rails/bin/sidekiq-cluster process_commit,post_receive
If you want to have one Sidekiq process dealing with the process_commit and
post_receive queues, and one process to process the gitlab_shell queue,
you'd use the following:
/opt/gitlab/embedded/service/gitlab-rails/bin/sidekiq-cluster process_commit,post_receive gitlab_shell
Monitoring the sidekiq-cluster command
The sidekiq-cluster command will not terminate once it has started the desired
amount of Sidekiq processes. Instead, the process will continue running and
forward any signals to the child processes. This makes it easy to stop all
Sidekiq processes as you simply send a signal to the sidekiq-cluster process,
instead of having to send it to the individual processes.
If the sidekiq-cluster process crashes or receives a SIGKILL, the child
processes will terminate themselves after a few seconds. This ensures you don't
end up with zombie Sidekiq processes.
All of this makes monitoring the processes fairly easy. Simply hook up
sidekiq-cluster to your supervisor of choice (e.g. runit) and you're good to
go.
If a child process died the sidekiq-cluster command will signal all remaining
process to terminate, then terminate itself. This removes the need for
sidekiq-cluster to re-implement complex process monitoring/restarting code.
Instead you should make sure your supervisor restarts the sidekiq-cluster
process whenever necessary.
PID files
The sidekiq-cluster command can store its PID in a file. By default no PID
file is written, but this can be changed by passing the --pidfile option to
sidekiq-cluster. For example:
/opt/gitlab/embedded/service/gitlab-rails/bin/sidekiq-cluster --pidfile /var/run/gitlab/sidekiq_cluster.pid process_commit
Keep in mind that the PID file will contain the PID of the sidekiq-cluster
command and not the PID(s) of the started Sidekiq processes.
Environment
The Rails environment can be set by passing the --environment flag to the
sidekiq-cluster command, or by setting RAILS_ENV to a non-empty value. The
default value can be found in /opt/gitlab/etc/gitlab-rails/env/RAILS_ENV.