16 KiB
Geo High Availability (PREMIUM ONLY)
This document describes a minimal reference architecture for running Geo in a high availability configuration. If your HA setup differs from the one described, it is possible to adapt these instructions to your needs.
Architecture overview
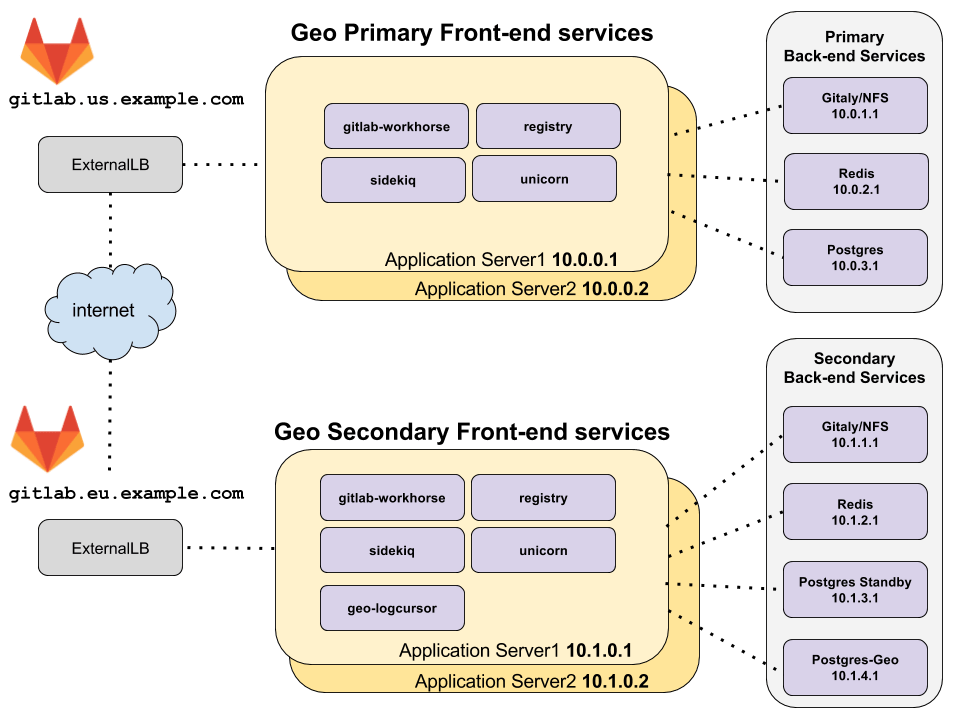
diagram source - GitLab employees only
The topology above assumes that the primary and secondary Geo clusters are located in two separate locations, on their own virtual network with private IP addresses. The network is configured such that all machines within one geographic location can communicate with each other using their private IP addresses. The IP addresses given are examples and may be different depending on the network topology of your deployment.
The only external way to access the two Geo deployments is by HTTPS at
gitlab.us.example.com and gitlab.eu.example.com in the example above.
NOTE: Note: The primary and secondary Geo deployments must be able to communicate to each other over HTTPS.
Redis and PostgreSQL High Availability
Geo supports:
- Redis and PostgreSQL on the primary node configured for high availability
- Redis on secondary nodes configured for high availability.
NOTE: Note: Support for PostgreSQL on secondary nodes in high availability configuration is planned.
Because of the additional complexity involved in setting up this configuration for PostgreSQL and Redis, it is not covered by this Geo HA documentation.
For more information about setting up a highly available PostgreSQL cluster and Redis cluster using the omnibus package see the high availability documentation for PostgreSQL and Redis, respectively.
NOTE: Note: It is possible to use cloud hosted services for PostgreSQL and Redis, but this is beyond the scope of this document.
Prerequisites: Two working GitLab HA clusters
One cluster will serve as the primary node. Use the GitLab HA documentation to set this up. If you already have a working GitLab instance that is in-use, it can be used as a primary.
The second cluster will serve as the secondary node. Again, use the GitLab HA documentation to set this up. It's a good idea to log in and test it, however, note that its data will be wiped out as part of the process of replicating from the primary.
Configure the GitLab cluster to be the primary node
The following steps enable a GitLab cluster to serve as the primary node.
Step 1: Configure the primary frontend servers
-
Edit
/etc/gitlab/gitlab.rband add the following:## ## Enable the Geo primary role ## roles ['geo_primary_role'] ## ## The unique identifier for the Geo node. ## gitlab_rails['geo_node_name'] = '<node_name_here>' ## ## Disable automatic migrations ## gitlab_rails['auto_migrate'] = false
After making these changes, reconfigure GitLab so the changes take effect.
NOTE: Note: PostgreSQL and Redis should have already been disabled on the application servers, and connections from the application servers to those services on the backend servers configured, during normal GitLab HA set up. See high availability configuration documentation for PostgreSQL and Redis.
Step 2: Configure the primary database
-
Edit
/etc/gitlab/gitlab.rband add the following:## ## Configure the Geo primary role and the PostgreSQL role ## roles ['geo_primary_role', 'postgres_role']
Configure a secondary node
A secondary cluster is similar to any other GitLab HA cluster, with two major differences:
- The main PostgreSQL database is a read-only replica of the primary node's PostgreSQL database.
- There is also a single PostgreSQL database for the secondary cluster, called the "tracking database", which tracks the synchronization state of various resources.
Therefore, we will set up the HA components one-by-one, and include deviations from the normal HA setup. However, we highly recommend first configuring a brand-new cluster as if it were not part of a Geo setup so that it can be tested and verified as a working cluster. And only then should it be modified for use as a Geo secondary. This helps to separate problems that are related and are not related to Geo setup.
Step 1: Configure the Redis and Gitaly services on the secondary node
Configure the following services, again using the non-Geo high availability documentation:
- Configuring Redis for GitLab HA for high availability.
- Gitaly, which will store data that is synchronized from the primary node.
NOTE: Note: NFS can be used in place of Gitaly but is not recommended.
Step 2: Configure the main read-only replica PostgreSQL database on the secondary node
NOTE: Note: The following documentation assumes the database will be run on a single node only. PostgreSQL HA on secondary nodes is not currently supported.
Configure the secondary database as a read-only replica of the primary database. Use the following as a guide.
-
Generate an MD5 hash of the desired password for the database user that the GitLab application will use to access the read-replica database:
Note that the username (
gitlabby default) is incorporated into the hash.gitlab-ctl pg-password-md5 gitlab # Enter password: <your_password_here> # Confirm password: <your_password_here> # fca0b89a972d69f00eb3ec98a5838484Use this hash to fill in
<md5_hash_of_your_password>in the next step. -
Edit
/etc/gitlab/gitlab.rbin the replica database machine, and add the following:## ## Configure the Geo secondary role and the PostgreSQL role ## roles ['geo_secondary_role', 'postgres_role'] ## ## Secondary address ## - replace '<secondary_node_ip>' with the public or VPC address of your Geo secondary node ## - replace '<tracking_database_ip>' with the public or VPC address of your Geo tracking database node ## postgresql['listen_address'] = '<secondary_node_ip>' postgresql['md5_auth_cidr_addresses'] = ['<secondary_node_ip>/32', '<tracking_database_ip>/32'] ## ## Database credentials password (defined previously in primary node) ## - replicate same values here as defined in primary node ## postgresql['sql_user_password'] = '<md5_hash_of_your_password>' gitlab_rails['db_password'] = '<your_password_here>' ## ## When running the Geo tracking database on a separate machine, disable it ## here and allow connections from the tracking database host. And ensure ## the tracking database IP is in postgresql['md5_auth_cidr_addresses'] above. ## geo_postgresql['enable'] = false ## ## Disable `geo_logcursor` service so Rails doesn't get configured here ## geo_logcursor['enable'] = false
After making these changes, reconfigure GitLab so the changes take effect.
If using an external PostgreSQL instance, refer also to Geo with external PostgreSQL instances.
Step 3: Configure the tracking database on the secondary node
NOTE: Note: This documentation assumes the tracking database will be run on only a single machine, rather than as a PostgreSQL cluster.
Configure the tracking database.
-
Generate an MD5 hash of the desired password for the database user that the GitLab application will use to access the tracking database:
Note that the username (
gitlab_geoby default) is incorporated into the hash.gitlab-ctl pg-password-md5 gitlab_geo # Enter password: <your_password_here> # Confirm password: <your_password_here> # fca0b89a972d69f00eb3ec98a5838484Use this hash to fill in
<tracking_database_password_md5_hash>in the next step. -
Edit
/etc/gitlab/gitlab.rbin the tracking database machine, and add the following:## ## Enable the Geo secondary tracking database ## geo_postgresql['enable'] = true geo_postgresql['listen_address'] = '<ip_address_of_this_host>' geo_postgresql['sql_user_password'] = '<tracking_database_password_md5_hash>' ## ## Configure FDW connection to the replica database ## geo_secondary['db_fdw'] = true geo_postgresql['fdw_external_password'] = '<replica_database_password_plaintext>' geo_postgresql['md5_auth_cidr_addresses'] = ['<replica_database_ip>/32'] gitlab_rails['db_host'] = '<replica_database_ip>' # Prevent reconfigure from attempting to run migrations on the replica DB gitlab_rails['auto_migrate'] = false ## ## Disable all other services that aren't needed, since we don't have a role ## that does this. ## alertmanager['enable'] = false consul['enable'] = false gitaly['enable'] = false gitlab_exporter['enable'] = false gitlab_workhorse['enable'] = false nginx['enable'] = false node_exporter['enable'] = false pgbouncer_exporter['enable'] = false postgresql['enable'] = false prometheus['enable'] = false redis['enable'] = false redis_exporter['enable'] = false repmgr['enable'] = false sidekiq['enable'] = false unicorn['enable'] = false
After making these changes, reconfigure GitLab so the changes take effect.
If using an external PostgreSQL instance, refer also to Geo with external PostgreSQL instances.
Step 4: Configure the frontend application servers on the secondary node
In the architecture overview, there are two machines running the GitLab application services. These services are enabled selectively in the configuration.
Configure the application servers following Configuring GitLab for HA, then make the following modifications:
-
Edit
/etc/gitlab/gitlab.rbon each application server in the secondary cluster, and add the following:## ## Enable the Geo secondary role ## roles ['geo_secondary_role', 'application_role'] ## ## The unique identifier for the Geo node. ## gitlab_rails['geo_node_name'] = '<node_name_here>' ## ## Disable automatic migrations ## gitlab_rails['auto_migrate'] = false ## ## Configure the connection to the tracking DB. And disable application ## servers from running tracking databases. ## geo_secondary['db_host'] = '<geo_tracking_db_host>' geo_secondary['db_password'] = '<geo_tracking_db_password>' geo_postgresql['enable'] = false ## ## Configure connection to the streaming replica database, if you haven't ## already ## gitlab_rails['db_host'] = '<replica_database_host>' gitlab_rails['db_password'] = '<replica_database_password>' ## ## Configure connection to Redis, if you haven't already ## gitlab_rails['redis_host'] = '<redis_host>' gitlab_rails['redis_password'] = '<redis_password>' ## ## If you are using custom users not managed by Omnibus, you need to specify ## UIDs and GIDs like below, and ensure they match between servers in a ## cluster to avoid permissions issues ## user['uid'] = 9000 user['gid'] = 9000 web_server['uid'] = 9001 web_server['gid'] = 9001 registry['uid'] = 9002 registry['gid'] = 9002
NOTE: Note:
If you had set up PostgreSQL cluster using the omnibus package and you had set
up postgresql['sql_user_password'] = 'md5 digest of secret' setting, keep in
mind that gitlab_rails['db_password'] and geo_secondary['db_password']
mentioned above contains the plaintext passwords. This is used to let the Rails
servers connect to the databases.
NOTE: Note:
Make sure that current node IP is listed in postgresql['md5_auth_cidr_addresses'] setting of your remote database.
After making these changes Reconfigure GitLab so the changes take effect.
On the secondary the following GitLab frontend services will be enabled:
geo-logcursorgitlab-pagesgitlab-workhorselogrotatenginxregistryremote-syslogsidekiqunicorn
Verify these services by running sudo gitlab-ctl status on the frontend
application servers.
Step 5: Set up the LoadBalancer for the secondary node
In this topology, a load balancer is required at each geographic location to route traffic to the application servers.
See Load Balancer for GitLab HA for more information.
Step 6: Configure the backend application servers on the secondary node
The minimal reference architecture diagram above shows all application services running together on the same machines. However, for high availability we strongly recommend running all services separately.
For example, a Sidekiq server could be configured similarly to the frontend
application servers above, with some changes to run only the sidekiq service:
-
Edit
/etc/gitlab/gitlab.rbon each Sidekiq server in the secondary cluster, and add the following:## ## Enable the Geo secondary role ## roles ['geo_secondary_role'] ## ## Enable the Sidekiq service ## sidekiq['enable'] = true ## ## Ensure unnecessary services are disabled ## alertmanager['enable'] = false consul['enable'] = false geo_logcursor['enable'] = false gitaly['enable'] = false gitlab_exporter['enable'] = false gitlab_workhorse['enable'] = false nginx['enable'] = false node_exporter['enable'] = false pgbouncer_exporter['enable'] = false postgresql['enable'] = false prometheus['enable'] = false redis['enable'] = false redis_exporter['enable'] = false repmgr['enable'] = false unicorn['enable'] = false ## ## The unique identifier for the Geo node. ## gitlab_rails['geo_node_name'] = '<node_name_here>' ## ## Disable automatic migrations ## gitlab_rails['auto_migrate'] = false ## ## Configure the connection to the tracking DB. And disable application ## servers from running tracking databases. ## geo_secondary['db_host'] = '<geo_tracking_db_host>' geo_secondary['db_password'] = '<geo_tracking_db_password>' geo_postgresql['enable'] = false ## ## Configure connection to the streaming replica database, if you haven't ## already ## gitlab_rails['db_host'] = '<replica_database_host>' gitlab_rails['db_password'] = '<replica_database_password>' ## ## Configure connection to Redis, if you haven't already ## gitlab_rails['redis_host'] = '<redis_host>' gitlab_rails['redis_password'] = '<redis_password>' ## ## If you are using custom users not managed by Omnibus, you need to specify ## UIDs and GIDs like below, and ensure they match between servers in a ## cluster to avoid permissions issues ## user['uid'] = 9000 user['gid'] = 9000 web_server['uid'] = 9001 web_server['gid'] = 9001 registry['uid'] = 9002 registry['gid'] = 9002You can similarly configure a server to run only the
geo-logcursorservice withgeo_logcursor['enable'] = trueand disabling Sidekiq withsidekiq['enable'] = false.These servers do not need to be attached to the load balancer.