32 KiB
| stage | group | info | type |
|---|---|---|---|
| Enablement | Geo | To determine the technical writer assigned to the Stage/Group associated with this page, see https://about.gitlab.com/handbook/engineering/ux/technical-writing/#designated-technical-writers | howto |
Troubleshooting Geo (PREMIUM ONLY)
Setting up Geo requires careful attention to details and sometimes it's easy to miss a step.
Here is a list of steps you should take to attempt to fix problem:
- Perform basic troubleshooting.
- Fix any replication errors.
- Fix any common errors.
Basic troubleshooting
Before attempting more advanced troubleshooting:
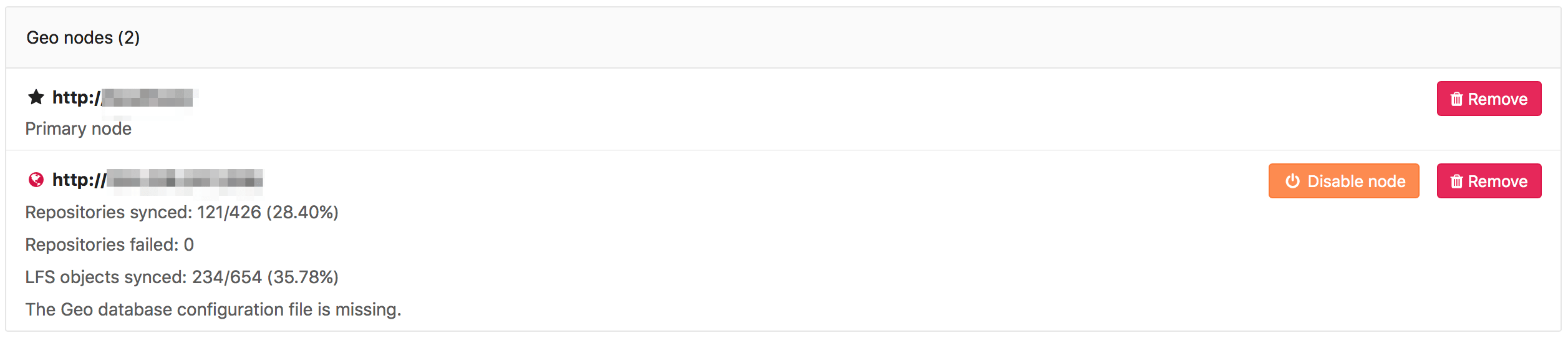
Check the health of the secondary node
Visit the primary node's Admin Area > Geo (/admin/geo/nodes) in
your browser. We perform the following health checks on each secondary node
to help identify if something is wrong:
- Is the node running?
- Is the node's secondary database configured for streaming replication?
- Is the node's secondary tracking database configured?
- Is the node's secondary tracking database connected?
- Is the node's secondary tracking database up-to-date?
For information on how to resolve common errors reported from the UI, see Fixing Common Errors.
If the UI is not working, or you are unable to log in, you can run the Geo health check manually to get this information as well as a few more details.
Health check Rake task
This Rake task can be run on an app node in the primary or secondary Geo nodes:
sudo gitlab-rake gitlab:geo:check
Example output:
Checking Geo ...
GitLab Geo is available ... yes
GitLab Geo is enabled ... yes
This machine's Geo node name matches a database record ... yes, found a secondary node named "Shanghai"
GitLab Geo secondary database is correctly configured ... yes
Database replication enabled? ... yes
Database replication working? ... yes
GitLab Geo HTTP(S) connectivity ...
* Can connect to the primary node ... yes
HTTP/HTTPS repository cloning is enabled ... yes
Machine clock is synchronized ... yes
Git user has default SSH configuration? ... yes
OpenSSH configured to use AuthorizedKeysCommand ... yes
GitLab configured to disable writing to authorized_keys file ... yes
GitLab configured to store new projects in hashed storage? ... yes
All projects are in hashed storage? ... yes
Checking Geo ... Finished
Sync status Rake task
Current sync information can be found manually by running this Rake task on any secondary app node:
sudo gitlab-rake geo:status
Example output:
http://secondary.example.com/
-----------------------------------------------------
GitLab Version: 11.10.4-ee
Geo Role: Secondary
Health Status: Healthy
Repositories: 289/289 (100%)
Verified Repositories: 289/289 (100%)
Wikis: 289/289 (100%)
Verified Wikis: 289/289 (100%)
LFS Objects: 8/8 (100%)
Attachments: 5/5 (100%)
CI job artifacts: 0/0 (0%)
Repositories Checked: 0/289 (0%)
Sync Settings: Full
Database replication lag: 0 seconds
Last event ID seen from primary: 10215 (about 2 minutes ago)
Last event ID processed by cursor: 10215 (about 2 minutes ago)
Last status report was: 2 minutes ago
Check if PostgreSQL replication is working
To check if PostgreSQL replication is working, check if:
Are nodes pointing to the correct database instance?
You should make sure your primary Geo node points to the instance with writing permissions.
Any secondary nodes should point only to read-only instances.
Can Geo detect the current node correctly?
Geo finds the current machine's Geo node name in /etc/gitlab/gitlab.rb by:
- Using the
gitlab_rails['geo_node_name']setting. - If that is not defined, using the
external_urlsetting.
This name is used to look up the node with the same Name in Admin Area > Geo.
To check if the current machine has a node name that matches a node in the database, run the check task:
sudo gitlab-rake gitlab:geo:check
It displays the current machine's node name and whether the matching database record is a primary or secondary node.
This machine's Geo node name matches a database record ... yes, found a secondary node named "Shanghai"
This machine's Geo node name matches a database record ... no
Try fixing it:
You could add or update a Geo node database record, setting the name to "https://example.com/".
Or you could set this machine's Geo node name to match the name of an existing database record: "London", "Shanghai"
For more information see:
doc/administration/geo/replication/troubleshooting.md#can-geo-detect-the-current-node-correctly
Fixing errors found when running the Geo check Rake task
When running this Rake task, you may see errors if the nodes are not properly configured:
sudo gitlab-rake gitlab:geo:check
-
Rails did not provide a password when connecting to the database
Checking Geo ... GitLab Geo is available ... Exception: fe_sendauth: no password supplied GitLab Geo is enabled ... Exception: fe_sendauth: no password supplied ... Checking Geo ... Finished- Ensure that you have the
gitlab_rails['db_password']set to the plain text-password used when creating the hash forpostgresql['sql_user_password'].
- Ensure that you have the
-
Rails is unable to connect to the database
Checking Geo ... GitLab Geo is available ... Exception: FATAL: no pg_hba.conf entry for host "1.1.1.1", user "gitlab", database "gitlabhq_production", SSL on FATAL: no pg_hba.conf entry for host "1.1.1.1", user "gitlab", database "gitlabhq_production", SSL off GitLab Geo is enabled ... Exception: FATAL: no pg_hba.conf entry for host "1.1.1.1", user "gitlab", database "gitlabhq_production", SSL on FATAL: no pg_hba.conf entry for host "1.1.1.1", user "gitlab", database "gitlabhq_production", SSL off ... Checking Geo ... Finished- Ensure that you have the IP address of the rails node included in
postgresql['md5_auth_cidr_addresses']. - Ensure that you have included the subnet mask on the IP address:
postgresql['md5_auth_cidr_addresses'] = ['1.1.1.1/32'].
- Ensure that you have the IP address of the rails node included in
-
Rails has supplied the incorrect password
Checking Geo ... GitLab Geo is available ... Exception: FATAL: password authentication failed for user "gitlab" FATAL: password authentication failed for user "gitlab" GitLab Geo is enabled ... Exception: FATAL: password authentication failed for user "gitlab" FATAL: password authentication failed for user "gitlab" ... Checking Geo ... Finished- Verify the correct password is set for
gitlab_rails['db_password']that was used when creating the hash inpostgresql['sql_user_password']by runninggitlab-ctl pg-password-md5 gitlaband entering the password.
- Verify the correct password is set for
-
Check returns
not a secondary nodeChecking Geo ... GitLab Geo is available ... yes GitLab Geo is enabled ... yes GitLab Geo secondary database is correctly configured ... not a secondary node Database replication enabled? ... not a secondary node ... Checking Geo ... Finished- Ensure that you have added the secondary node in the Admin Area of the primary node.
- Ensure that you entered the
external_urlorgitlab_rails['geo_node_name']when adding the secondary node in the admin are of the primary node. - Prior to GitLab 12.4, edit the secondary node in the Admin Area of the primary node and ensure that there is a trailing
/in theNamefield.
-
Check returns
Exception: PG::UndefinedTable: ERROR: relation "geo_nodes" does not existChecking Geo ... GitLab Geo is available ... no Try fixing it: Upload a new license that includes the GitLab Geo feature For more information see: https://about.gitlab.com/features/gitlab-geo/ GitLab Geo is enabled ... Exception: PG::UndefinedTable: ERROR: relation "geo_nodes" does not exist LINE 8: WHERE a.attrelid = '"geo_nodes"'::regclass ^ : SELECT a.attname, format_type(a.atttypid, a.atttypmod), pg_get_expr(d.adbin, d.adrelid), a.attnotnull, a.atttypid, a.atttypmod, c.collname, col_description(a.attrelid, a.attnum) AS comment FROM pg_attribute a LEFT JOIN pg_attrdef d ON a.attrelid = d.adrelid AND a.attnum = d.adnum LEFT JOIN pg_type t ON a.atttypid = t.oid LEFT JOIN pg_collation c ON a.attcollation = c.oid AND a.attcollation <> t.typcollation WHERE a.attrelid = '"geo_nodes"'::regclass AND a.attnum > 0 AND NOT a.attisdropped ORDER BY a.attnum ... Checking Geo ... FinishedWhen performing a PostgreSQL major version (9 > 10) update this is expected. Follow:
Fixing replication errors
The following sections outline troubleshooting steps for fixing replication
errors (indicated by Database replication working? ... no in the
geo:check output.
Message: ERROR: replication slots can only be used if max_replication_slots > 0?
This means that the max_replication_slots PostgreSQL variable needs to
be set on the primary database. In GitLab 9.4, we have made this setting
default to 1. You may need to increase this value if you have more
secondary nodes.
Be sure to restart PostgreSQL for this to take effect. See the PostgreSQL replication setup guide for more details.
Message: FATAL: could not start WAL streaming: ERROR: replication slot "geo_secondary_my_domain_com" does not exist?
This occurs when PostgreSQL does not have a replication slot for the secondary node by that name.
You may want to rerun the replication process on the secondary node .
Message: "Command exceeded allowed execution time" when setting up replication?
This may happen while initiating the replication process on the secondary node, and indicates that your initial dataset is too large to be replicated in the default timeout (30 minutes).
Re-run gitlab-ctl replicate-geo-database, but include a larger value for
--backup-timeout:
sudo gitlab-ctl \
replicate-geo-database \
--host=<primary_node_hostname> \
--slot-name=<secondary_slot_name> \
--backup-timeout=21600
This will give the initial replication up to six hours to complete, rather than the default thirty minutes. Adjust as required for your installation.
Message: "PANIC: could not write to file pg_xlog/xlogtemp.123: No space left on device"
Determine if you have any unused replication slots in the primary database. This can cause large amounts of
log data to build up in pg_xlog. Removing the unused slots can reduce the amount of space used in the pg_xlog.
-
Start a PostgreSQL console session:
sudo gitlab-psqlNote: Note: Using
gitlab-rails dbconsolewill not work, because managing replication slots requires superuser permissions. -
View your replication slots with:
SELECT * FROM pg_replication_slots;
Slots where active is f are not active.
-
When this slot should be active, because you have a secondary node configured using that slot, log in to that secondary node and check the PostgreSQL logs why the replication is not running.
-
If you are no longer using the slot (e.g. you no longer have Geo enabled), you can remove it with in the PostgreSQL console session:
SELECT pg_drop_replication_slot('<name_of_extra_slot>');
Message: "ERROR: canceling statement due to conflict with recovery"
This error may rarely occur under normal usage, and the system is resilient enough to recover.
However, under certain conditions, some database queries on secondaries may run excessively long, which increases the frequency of this error. At some point, some of these queries will never be able to complete due to being canceled every time.
These long-running queries are
planned to be removed in the future,
but as a workaround, we recommend enabling
hot_standby_feedback.
This increases the likelihood of bloat on the primary node as it prevents
VACUUM from removing recently-dead rows. However, it has been used
successfully in production on GitLab.com.
To enable hot_standby_feedback, add the following to /etc/gitlab/gitlab.rb
on the secondary node:
postgresql['hot_standby_feedback'] = 'on'
Then reconfigure GitLab:
sudo gitlab-ctl reconfigure
To help us resolve this problem, consider commenting on the issue.
Message: LOG: invalid CIDR mask in address
This happens on wrongly-formatted addresses in postgresql['md5_auth_cidr_addresses'].
2020-03-20_23:59:57.60499 LOG: invalid CIDR mask in address "***"
2020-03-20_23:59:57.60501 CONTEXT: line 74 of configuration file "/var/opt/gitlab/postgresql/data/pg_hba.conf"
To fix this, update the IP addresses in /etc/gitlab/gitlab.rb under postgresql['md5_auth_cidr_addresses']
to respect the CIDR format (i.e. 1.2.3.4/32).
Message: LOG: invalid IP mask "md5": Name or service not known
This happens when you have added IP addresses without a subnet mask in postgresql['md5_auth_cidr_addresses'].
2020-03-21_00:23:01.97353 LOG: invalid IP mask "md5": Name or service not known
2020-03-21_00:23:01.97354 CONTEXT: line 75 of configuration file "/var/opt/gitlab/postgresql/data/pg_hba.conf"
To fix this, add the subnet mask in /etc/gitlab/gitlab.rb under postgresql['md5_auth_cidr_addresses']
to respect the CIDR format (i.e. 1.2.3.4/32).
Very large repositories never successfully synchronize on the secondary node
GitLab places a timeout on all repository clones, including project imports
and Geo synchronization operations. If a fresh git clone of a repository
on the primary takes more than the default three hours, you may be affected by this.
To increase the timeout, add the following line to /etc/gitlab/gitlab.rb
on the secondary node:
gitlab_rails['gitlab_shell_git_timeout'] = 14400
Then reconfigure GitLab:
sudo gitlab-ctl reconfigure
This will increase the timeout to four hours (14400 seconds). Choose a time long enough to accommodate a full clone of your largest repositories.
New LFS objects are never replicated
If new LFS objects are never replicated to secondary Geo nodes, check the version of GitLab you are running. GitLab versions 11.11.x or 12.0.x are affected by a bug that results in new LFS objects not being replicated to Geo secondary nodes.
To resolve the issue, upgrade to GitLab 12.1 or newer.
Resetting Geo secondary node replication
If you get a secondary node in a broken state and want to reset the replication state, to start again from scratch, there are a few steps that can help you:
-
Stop Sidekiq and the Geo LogCursor
It's possible to make Sidekiq stop gracefully, but making it stop getting new jobs and wait until the current jobs to finish processing.
You need to send a SIGTSTP kill signal for the first phase and them a SIGTERM when all jobs have finished. Otherwise just use the
gitlab-ctl stopcommands.gitlab-ctl status sidekiq # run: sidekiq: (pid 10180) <- this is the PID you will use kill -TSTP 10180 # change to the correct PID gitlab-ctl stop sidekiq gitlab-ctl stop geo-logcursorYou can watch Sidekiq logs to know when Sidekiq jobs processing have finished:
gitlab-ctl tail sidekiq -
Rename repository storage folders and create new ones. If you are not concerned about possible orphaned directories and files, then you can simply skip this step.
mv /var/opt/gitlab/git-data/repositories /var/opt/gitlab/git-data/repositories.old mkdir -p /var/opt/gitlab/git-data/repositories chown git:git /var/opt/gitlab/git-data/repositoriesTIP: Tip: You may want to remove the
/var/opt/gitlab/git-data/repositories.oldin the future as soon as you confirmed that you don't need it anymore, to save disk space. -
(Optional) Rename other data folders and create new ones
CAUTION: Caution: You may still have files on the secondary node that have been removed from primary node but removal have not been reflected. If you skip this step, they will never be removed from this Geo node.
Any uploaded content like file attachments, avatars or LFS objects are stored in a subfolder in one of the two paths below:
/var/opt/gitlab/gitlab-rails/shared/var/opt/gitlab/gitlab-rails/uploads
To rename all of them:
gitlab-ctl stop mv /var/opt/gitlab/gitlab-rails/shared /var/opt/gitlab/gitlab-rails/shared.old mkdir -p /var/opt/gitlab/gitlab-rails/shared mv /var/opt/gitlab/gitlab-rails/uploads /var/opt/gitlab/gitlab-rails/uploads.old mkdir -p /var/opt/gitlab/gitlab-rails/uploads gitlab-ctl start geo-postgresqlReconfigure in order to recreate the folders and make sure permissions and ownership are correctly
gitlab-ctl reconfigure -
Reset the Tracking Database
gitlab-rake geo:db:drop # on a secondary app node gitlab-ctl reconfigure # on the tracking database node gitlab-rake geo:db:setup # on a secondary app node -
Restart previously stopped services
gitlab-ctl start
Fixing errors during a PostgreSQL upgrade or downgrade
Message: ERROR: psql: FATAL: role "gitlab-consul" does not exist
When upgrading PostgreSQL on a Geo instance, you might encounter the following error:
$ sudo gitlab-ctl pg-upgrade --target-version=11
Checking for an omnibus managed postgresql: OK
Checking if postgresql['version'] is set: OK
Checking if we already upgraded: NOT OK
Checking for a newer version of PostgreSQL to install
Upgrading PostgreSQL to 11.7
Checking if PostgreSQL bin files are symlinked to the expected location: OK
Waiting 30 seconds to ensure tasks complete before PostgreSQL upgrade.
See https://docs.gitlab.com/omnibus/settings/database.html#upgrade-packaged-postgresql-server for details
If you do not want to upgrade the PostgreSQL server at this time, enter Ctrl-C and see the documentation for details
Please hit Ctrl-C now if you want to cancel the operation.
..............................Detected an HA cluster.
Error running command: /opt/gitlab/embedded/bin/psql -qt -d gitlab_repmgr -h /var/opt/gitlab/postgresql -p 5432 -c "SELECT name FROM repmgr_gitlab_cluster.repl_nodes WHERE type='master' AND active != 'f'" -U gitlab-consul
ERROR: psql: FATAL: role "gitlab-consul" does not exist
Traceback (most recent call last):
10: from /opt/gitlab/embedded/bin/omnibus-ctl:23:in `<main>'
9: from /opt/gitlab/embedded/bin/omnibus-ctl:23:in `load'
8: from /opt/gitlab/embedded/lib/ruby/gems/2.6.0/gems/omnibus-ctl-0.6.0/bin/omnibus-ctl:31:in `<top (required)>'
7: from /opt/gitlab/embedded/lib/ruby/gems/2.6.0/gems/omnibus-ctl-0.6.0/lib/omnibus-ctl.rb:746:in `run'
6: from /opt/gitlab/embedded/lib/ruby/gems/2.6.0/gems/omnibus-ctl-0.6.0/lib/omnibus-ctl.rb:204:in `block in add_command_under_category'
5: from /opt/gitlab/embedded/service/omnibus-ctl/pg-upgrade.rb:171:in `block in load_file'
4: from /opt/gitlab/embedded/service/omnibus-ctl-ee/lib/repmgr.rb:248:in `is_master?'
3: from /opt/gitlab/embedded/service/omnibus-ctl-ee/lib/repmgr.rb:100:in `execute_psql'
2: from /opt/gitlab/embedded/service/omnibus-ctl-ee/lib/repmgr.rb:113:in `cmd'
1: from /opt/gitlab/embedded/lib/ruby/gems/2.6.0/gems/mixlib-shellout-3.0.9/lib/mixlib/shellout.rb:287:in `error!'
/opt/gitlab/embedded/lib/ruby/gems/2.6.0/gems/mixlib-shellout-3.0.9/lib/mixlib/shellout.rb:300:in `invalid!': Expected process to exit with [0], but received '2' (Mixlib::ShellOut::ShellCommandFailed)
---- Begin output of /opt/gitlab/embedded/bin/psql -qt -d gitlab_repmgr -h /var/opt/gitlab/postgresql -p 5432 -c "SELECT name FROM repmgr_gitlab_cluster.repl_nodes WHERE type='master' AND active != 'f'" -U gitlab-consul ----
STDOUT:
STDERR: psql: FATAL: role "gitlab-consul" does not exist
---- End output of /opt/gitlab/embedded/bin/psql -qt -d gitlab_repmgr -h /var/opt/gitlab/postgresql -p 5432 -c "SELECT name FROM repmgr_gitlab_cluster.repl_nodes WHERE type='master' AND active != 'f'" -U gitlab-consul ----
Ran /opt/gitlab/embedded/bin/psql -qt -d gitlab_repmgr -h /var/opt/gitlab/postgresql -p 5432 -c "SELECT name FROM repmgr_gitlab_cluster.repl_nodes WHERE type='master' AND active != 'f'" -U gitlab-consul returned 2
If you are upgrading the PostgreSQL read-replica of a Geo secondary node, and
you are not using consul or repmgr, you may need to disable consul and/or
repmgr services in gitlab.rb:
consul['enable'] = false
repmgr['enable'] = false
Then reconfigure GitLab:
sudo gitlab-ctl reconfigure
Fixing errors during a failover or when promoting a secondary to a primary node
The following are possible errors that might be encountered during failover or when promoting a secondary to a primary node with strategies to resolve them.
Message: ActiveRecord::RecordInvalid: Validation failed: Name has already been taken
When promoting a secondary node, you might encounter the following error:
Running gitlab-rake geo:set_secondary_as_primary...
rake aborted!
ActiveRecord::RecordInvalid: Validation failed: Name has already been taken
/opt/gitlab/embedded/service/gitlab-rails/ee/lib/tasks/geo.rake:236:in `block (3 levels) in <top (required)>'
/opt/gitlab/embedded/service/gitlab-rails/ee/lib/tasks/geo.rake:221:in `block (2 levels) in <top (required)>'
/opt/gitlab/embedded/bin/bundle:23:in `load'
/opt/gitlab/embedded/bin/bundle:23:in `<main>'
Tasks: TOP => geo:set_secondary_as_primary
(See full trace by running task with --trace)
You successfully promoted this node!
If you encounter this message when running gitlab-rake geo:set_secondary_as_primary
or gitlab-ctl promote-to-primary-node, either:
-
Enter a Rails console and run:
Rails.application.load_tasks; nil Gitlab::Geo.expire_cache! Rake::Task['geo:set_secondary_as_primary'].invoke -
Upgrade to GitLab 12.6.3 or newer if it is safe to do so. For example, if the failover was just a test. A caching-related bug was fixed.
Message: ActiveRecord::RecordInvalid: Validation failed: Enabled Geo primary node cannot be disabled
This error may occur if you have paused replication from the original primary node before attempting to promote this node. To double check this, you can do the following:
-
Get the current secondary node's ID using:
sudo gitlab-rails runner 'puts GeoNode.current_node.id' -
Double check that the node is active through the database by running the following on the secondary node, replacing
ID_FROM_ABOVE:sudo gitlab-rails dbconsole SELECT enabled FROM geo_nodes WHERE id = ID_FROM_ABOVE; -
If the above returned
fit means that the replication was paused. You can re-enable it through anUPDATEstatement in the database:sudo gitlab-rails dbconsole UPDATE geo_nodes SET enabled = 't' WHERE id = ID_FROM_ABOVE;
While Promoting the secondary, I got an error ActiveRecord::RecordInvalid
If you disabled a secondary node, either with the replication pause task (13.2) or via the UI (13.1 and earlier), you must first re-enable the node before you can continue. This is fixed in 13.4.
From gitlab-psql, execute the following, replacing <your secondary url>
with the URL for your secondary server starting with http or https and ending with a /.
SECONDARY_URL="https://<secondary url>/"
DATABASE_NAME="gitlabhq_production"
sudo gitlab-psql -d "$DATABASE_NAME" -c "UPDATE geo_nodes SET enabled = true WHERE url = '$SECONDARY_URL';"
This should update 1 row.
Message: NoMethodError: undefined method `secondary?' for nil:NilClass
When promoting a secondary node, you might encounter the following error:
sudo gitlab-rake geo:set_secondary_as_primary
rake aborted!
NoMethodError: undefined method `secondary?' for nil:NilClass
/opt/gitlab/embedded/service/gitlab-rails/ee/lib/tasks/geo.rake:232:in `block (3 levels) in <top (required)>'
/opt/gitlab/embedded/service/gitlab-rails/ee/lib/tasks/geo.rake:221:in `block (2 levels) in <top (required)>'
/opt/gitlab/embedded/bin/bundle:23:in `load'
/opt/gitlab/embedded/bin/bundle:23:in `<main>'
Tasks: TOP => geo:set_secondary_as_primary
(See full trace by running task with --trace)
This command is intended to be executed on a secondary node only, and this error is displayed if you attempt to run this command on a primary node.
Message: sudo: gitlab-pg-ctl: command not found
When
promoting a secondary node with multiple servers,
you need to run the gitlab-pg-ctl command to promote the PostgreSQL
read-replica database.
In GitLab 12.8 and earlier, this command will fail with the message:
sudo: gitlab-pg-ctl: command not found
In this case, the workaround is to use the full path to the binary, for example:
sudo /opt/gitlab/embedded/bin/gitlab-pg-ctl promote
GitLab 12.9 and later are unaffected by this error.
Two-factor authentication is broken after a failover
The setup instructions for Geo prior to 10.5 failed to replicate the
otp_key_base secret, which is used to encrypt the two-factor authentication
secrets stored in the database. If it differs between primary and secondary
nodes, users with two-factor authentication enabled won't be able to log in
after a failover.
If you still have access to the old primary node, you can follow the instructions in the Upgrading to GitLab 10.5 section to resolve the error. Otherwise, the secret is lost and you'll need to reset two-factor authentication for all users.
Expired artifacts
If you notice for some reason there are more artifacts on the Geo secondary node than on the Geo primary node, you can use the Rake task to cleanup orphan artifact files.
On a Geo secondary node, this command will also clean up all Geo registry record related to the orphan files on disk.
Fixing sign in errors
Message: The redirect URI included is not valid
If you are able to log in to the primary node, but you receive this error when attempting to log into a secondary, you should check that the Geo node's URL matches its external URL.
- On the primary, visit Admin Area > Geo.
- Find the affected secondary and click Edit.
- Ensure the URL field matches the value found in
/etc/gitlab/gitlab.rbinexternal_url "https://gitlab.example.com"on the frontend server(s) of the secondary node.
Fixing common errors
This section documents common errors reported in the Admin UI and how to fix them.
Geo database configuration file is missing
GitLab cannot find or doesn't have permission to access the database_geo.yml configuration file.
In an Omnibus GitLab installation, the file should be in /var/opt/gitlab/gitlab-rails/etc.
If it doesn't exist or inadvertent changes have been made to it, run sudo gitlab-ctl reconfigure to restore it to its correct state.
If this path is mounted on a remote volume, please check your volume configuration and that it has correct permissions.
An existing tracking database cannot be reused
Geo cannot reuse an existing tracking database.
It is safest to use a fresh secondary, or reset the whole secondary by following Resetting Geo secondary node replication.
Geo node has a database that is writable which is an indication it is not configured for replication with the primary node
This error refers to a problem with the database replica on a secondary node, which Geo expects to have access to. It usually means, either:
- An unsupported replication method was used (for example, logical replication).
- The instructions to setup a Geo database replication were not followed correctly.
- Your database connection details are incorrect, that is you have specified the wrong
user in your
/etc/gitlab/gitlab.rbfile.
A common source of confusion with secondary nodes is that it requires two separate PostgreSQL instances:
- A read-only replica of the primary node.
- A regular, writable instance that holds replication metadata. That is, the Geo tracking database.
Geo node does not appear to be replicating the database from the primary node
The most common problems that prevent the database from replicating correctly are:
- Secondary nodes cannot reach the primary node. Check credentials, firewall rules, etc.
- SSL certificate problems. Make sure you copied
/etc/gitlab/gitlab-secrets.jsonfrom the primary node. - Database storage disk is full.
- Database replication slot is misconfigured.
- Database is not using a replication slot or another alternative and cannot catch-up because WAL files were purged.
Make sure you follow the Geo database replication instructions for supported configuration.
Geo database version (...) does not match latest migration (...)
If you are using Omnibus GitLab installation, something might have failed during upgrade. You can:
- Run
sudo gitlab-ctl reconfigure. - Manually trigger the database migration by running:
sudo gitlab-rake geo:db:migrateas root on the secondary node.
GitLab indicates that more than 100% of repositories were synced
This can be caused by orphaned records in the project registry. You can clear them using a Rake task.
Geo Admin Area returns 404 error for a secondary node
Sometimes sudo gitlab-rake gitlab:geo:check indicates that the secondary node is
healthy, but a 404 error for the secondary node is returned in the Geo Admin Area on
the primary node.
To resolve this issue:
- Try restarting the secondary using
sudo gitlab-ctl restart. - Check
/var/log/gitlab/gitlab-rails/geo.logto see if the secondary node is using IPv6 to send its status to the primary node. If it is, add an entry to the primary node using IPv4 in the/etc/hostsfile. Alternatively, you should enable IPv6 on the primary node.