To avoid deadlock problem, almost database related functions should be
have ctx as the first parameter.
This PR do a refactor for some of these functions.
Close #25906

Succeeded logs:
```
[I] router: completed GET /root/test/issues/posters?&q=%20&_=1689853025011 for [::1]:59271, 200 OK in 127.7ms @ repo/issue.go:3505(repo.IssuePosters)
[I] router: completed GET /root/test/pulls/posters?&q=%20&_=1689853968204 for [::1]:59269, 200 OK in 94.3ms @ repo/issue.go:3509(repo.PullPosters)
```
A couple of notes:
* Future changes should refactor arguments into a struct
* This filtering only is supported by meilisearch right now
* Issue index number is bumped which will cause a re-index
Related #14180
Related #25233
Related #22639
Close #19786
Related #12763
This PR will change all the branches retrieve method from reading git
data to read database to reduce git read operations.
- [x] Sync git branches information into database when push git data
- [x] Create a new table `Branch`, merge some columns of `DeletedBranch`
into `Branch` table and drop the table `DeletedBranch`.
- [x] Read `Branch` table when visit `code` -> `branch` page
- [x] Read `Branch` table when list branch names in `code` page dropdown
- [x] Read `Branch` table when list git ref compare page
- [x] Provide a button in admin page to manually sync all branches.
- [x] Sync branches if repository is not empty but database branches are
empty when visiting pages with branches list
- [x] Use `commit_time desc` as the default FindBranch order by to keep
consistent as before and deleted branches will be always at the end.
---------
Co-authored-by: Jason Song <i@wolfogre.com>
Refactor `modules/indexer` to make it more maintainable. And it can be
easier to support more features. I'm trying to solve some of issue
searching, this is a precursor to making functional changes.
Current supported engines and the index versions:
| engines | issues | code |
| - | - | - |
| db | Just a wrapper for database queries, doesn't need version | - |
| bleve | The version of index is **2** | The version of index is **6**
|
| elasticsearch | The old index has no version, will be treated as
version **0** in this PR | The version of index is **1** |
| meilisearch | The old index has no version, will be treated as version
**0** in this PR | - |
## Changes
### Split
Splited it into mutiple packages
```text
indexer
├── internal
│ ├── bleve
│ ├── db
│ ├── elasticsearch
│ └── meilisearch
├── code
│ ├── bleve
│ ├── elasticsearch
│ └── internal
└── issues
├── bleve
├── db
├── elasticsearch
├── internal
└── meilisearch
```
- `indexer/interanal`: Internal shared package for indexer.
- `indexer/interanal/[engine]`: Internal shared package for each engine
(bleve/db/elasticsearch/meilisearch).
- `indexer/code`: Implementations for code indexer.
- `indexer/code/internal`: Internal shared package for code indexer.
- `indexer/code/[engine]`: Implementation via each engine for code
indexer.
- `indexer/issues`: Implementations for issues indexer.
### Deduplication
- Combine `Init/Ping/Close` for code indexer and issues indexer.
- ~Combine `issues.indexerHolder` and `code.wrappedIndexer` to
`internal.IndexHolder`.~ Remove it, use dummy indexer instead when the
indexer is not ready.
- Duplicate two copies of creating ES clients.
- Duplicate two copies of `indexerID()`.
### Enhancement
- [x] Support index version for elasticsearch issues indexer, the old
index without version will be treated as version 0.
- [x] Fix spell of `elastic_search/ElasticSearch`, it should be
`Elasticsearch`.
- [x] Improve versioning of ES index. We don't need `Aliases`:
- Gitea does't need aliases for "Zero Downtime" because it never delete
old indexes.
- The old code of issues indexer uses the orignal name to create issue
index, so it's tricky to convert it to an alias.
- [x] Support index version for meilisearch issues indexer, the old
index without version will be treated as version 0.
- [x] Do "ping" only when `Ping` has been called, don't ping
periodically and cache the status.
- [x] Support the context parameter whenever possible.
- [x] Fix outdated example config.
- [x] Give up the requeue logic of issues indexer: When indexing fails,
call Ping to check if it was caused by the engine being unavailable, and
only requeue the task if the engine is unavailable.
- It is fragile and tricky, could cause data losing (It did happen when
I was doing some tests for this PR). And it works for ES only.
- Just always requeue the failed task, if it caused by bad data, it's a
bug of Gitea which should be fixed.
---------
Co-authored-by: Giteabot <teabot@gitea.io>
this will allow us to fully localize it later
PS: we can not migrate back as the old value was a one-way conversion
prepare for #25213
---
*Sponsored by Kithara Software GmbH*
This PR replaces all string refName as a type `git.RefName` to make the
code more maintainable.
Fix #15367
Replaces #23070
It also fixed a bug that tags are not sync because `git remote --prune
origin` will not remove local tags if remote removed.
We in fact should use `git fetch --prune --tags origin` but not `git
remote update origin` to do the sync.
Some answer from ChatGPT as ref.
> If the git fetch --prune --tags command is not working as expected,
there could be a few reasons why. Here are a few things to check:
>
>Make sure that you have the latest version of Git installed on your
system. You can check the version by running git --version in your
terminal. If you have an outdated version, try updating Git and see if
that resolves the issue.
>
>Check that your Git repository is properly configured to track the
remote repository's tags. You can check this by running git config
--get-all remote.origin.fetch and verifying that it includes
+refs/tags/*:refs/tags/*. If it does not, you can add it by running git
config --add remote.origin.fetch "+refs/tags/*:refs/tags/*".
>
>Verify that the tags you are trying to prune actually exist on the
remote repository. You can do this by running git ls-remote --tags
origin to list all the tags on the remote repository.
>
>Check if any local tags have been created that match the names of tags
on the remote repository. If so, these local tags may be preventing the
git fetch --prune --tags command from working properly. You can delete
local tags using the git tag -d command.
---------
Co-authored-by: delvh <dev.lh@web.de>
This adds the ability to pin important Issues and Pull Requests. You can
also move pinned Issues around to change their Position. Resolves #2175.
## Screenshots
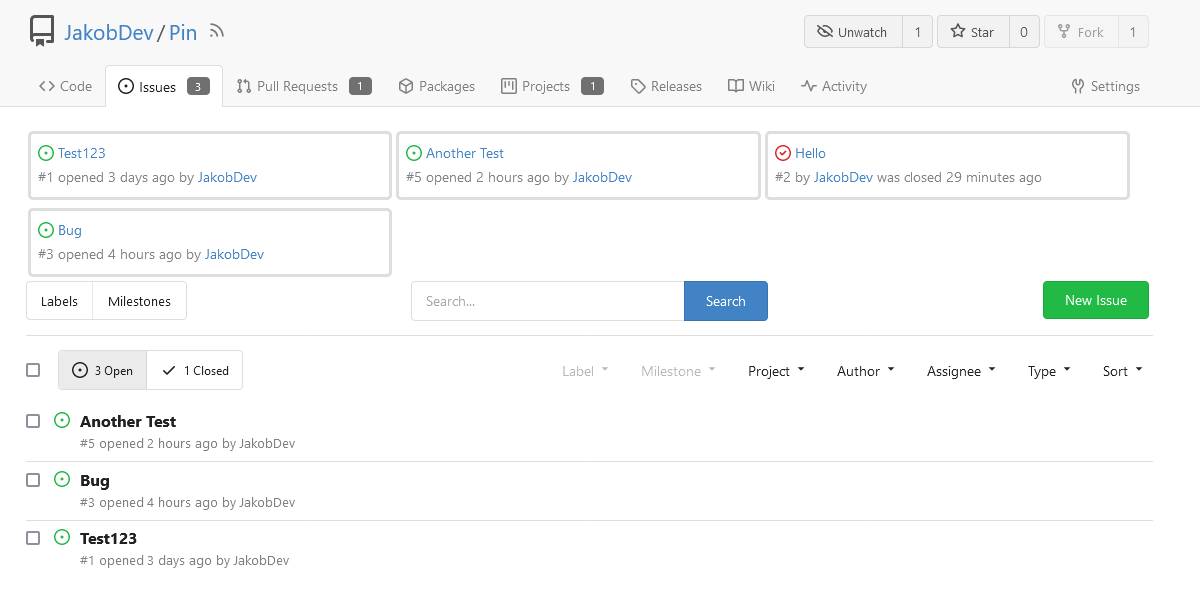
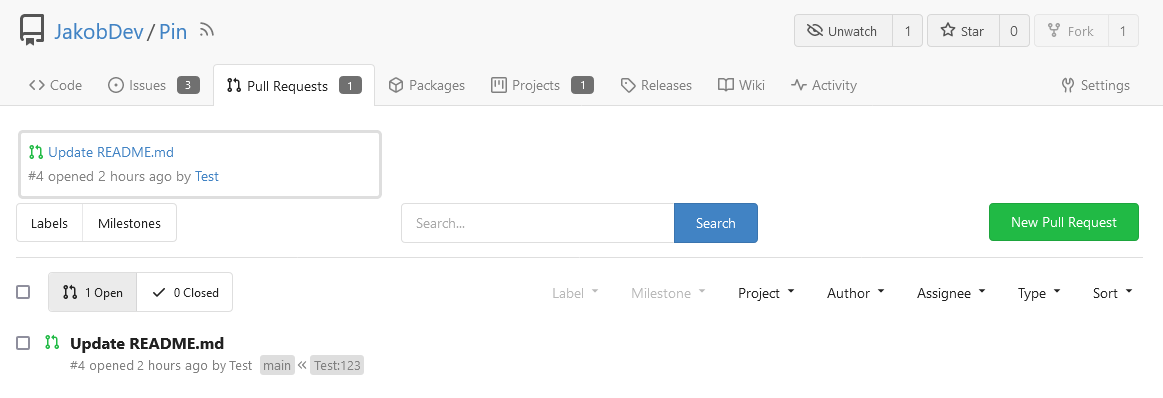
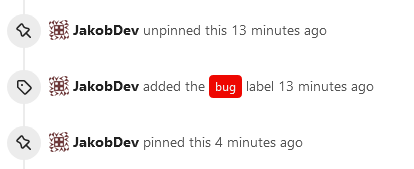
The Design was mostly copied from the Projects Board.
## Implementation
This uses a new `pin_order` Column in the `issue` table. If the value is
set to 0, the Issue is not pinned. If it's set to a bigger value, the
value is the Position. 1 means it's the first pinned Issue, 2 means it's
the second one etc. This is dived into Issues and Pull requests for each
Repo.
## TODO
- [x] You can currently pin as many Issues as you want. Maybe we should
add a Limit, which is configurable. GitHub uses 3, but I prefer 6, as
this is better for bigger Projects, but I'm open for suggestions.
- [x] Pin and Unpin events need to be added to the Issue history.
- [x] Tests
- [x] Migration
**The feature itself is currently fully working, so tester who may find
weird edge cases are very welcome!**
---------
Co-authored-by: silverwind <me@silverwind.io>
Co-authored-by: Giteabot <teabot@gitea.io>
close https://github.com/go-gitea/gitea/issues/16321
Provided a webhook trigger for requesting someone to review the Pull
Request.
Some modifications have been made to the returned `PullRequestPayload`
based on the GitHub webhook settings, including:
- add a description of the current reviewer object as
`RequestedReviewer` .
- setting the action to either **review_requested** or
**review_request_removed** based on the operation.
- adding the `RequestedReviewers` field to the issues_model.PullRequest.
This field will be loaded into the PullRequest through
`LoadRequestedReviewers()` when `ToAPIPullRequest` is called.
After the Pull Request is merged, I will supplement the relevant
documentation.
## ⚠️ Breaking
The `log.<mode>.<logger>` style config has been dropped. If you used it,
please check the new config manual & app.example.ini to make your
instance output logs as expected.
Although many legacy options still work, it's encouraged to upgrade to
the new options.
The SMTP logger is deleted because SMTP is not suitable to collect logs.
If you have manually configured Gitea log options, please confirm the
logger system works as expected after upgrading.
## Description
Close #12082 and maybe more log-related issues, resolve some related
FIXMEs in old code (which seems unfixable before)
Just like rewriting queue #24505 : make code maintainable, clear legacy
bugs, and add the ability to support more writers (eg: JSON, structured
log)
There is a new document (with examples): `logging-config.en-us.md`
This PR is safer than the queue rewriting, because it's just for
logging, it won't break other logic.
## The old problems
The logging system is quite old and difficult to maintain:
* Unclear concepts: Logger, NamedLogger, MultiChannelledLogger,
SubLogger, EventLogger, WriterLogger etc
* Some code is diffuclt to konw whether it is right:
`log.DelNamedLogger("console")` vs `log.DelNamedLogger(log.DEFAULT)` vs
`log.DelLogger("console")`
* The old system heavily depends on ini config system, it's difficult to
create new logger for different purpose, and it's very fragile.
* The "color" trick is difficult to use and read, many colors are
unnecessary, and in the future structured log could help
* It's difficult to add other log formats, eg: JSON format
* The log outputer doesn't have full control of its goroutine, it's
difficult to make outputer have advanced behaviors
* The logs could be lost in some cases: eg: no Fatal error when using
CLI.
* Config options are passed by JSON, which is quite fragile.
* INI package makes the KEY in `[log]` section visible in `[log.sub1]`
and `[log.sub1.subA]`, this behavior is quite fragile and would cause
more unclear problems, and there is no strong requirement to support
`log.<mode>.<logger>` syntax.
## The new design
See `logger.go` for documents.
## Screenshot
<details>



</details>
## TODO
* [x] add some new tests
* [x] fix some tests
* [x] test some sub-commands (manually ....)
---------
Co-authored-by: Jason Song <i@wolfogre.com>
Co-authored-by: delvh <dev.lh@web.de>
Co-authored-by: Giteabot <teabot@gitea.io>
Replace #16455
Close #21803
Mixing different Gitea contexts together causes some problems:
1. Unable to respond proper content when error occurs, eg: Web should
respond HTML while API should respond JSON
2. Unclear dependency, eg: it's unclear when Context is used in
APIContext, which fields should be initialized, which methods are
necessary.
To make things clear, this PR introduces a Base context, it only
provides basic Req/Resp/Data features.
This PR mainly moves code. There are still many legacy problems and
TODOs in code, leave unrelated changes to future PRs.
This PR
- [x] Move some functions from `issues.go` to `issue_stats.go` and
`issue_label.go`
- [x] Remove duplicated issue options `UserIssueStatsOption` to keep
only one `IssuesOptions`
This PR
- [x] Move some code from `issue.go` to `issue_search.go` and
`issue_update.go`
- [x] Use `IssuesOptions` instead of `IssueStatsOptions` becuase they
are too similiar.
- [x] Rename some functions
1. Remove unused fields/methods in web context.
2. Make callers call target function directly instead of the light
wrapper like "IsUserRepoReaderSpecific"
3. The "issue template" code shouldn't be put in the "modules/context"
package, so move them to the service package.
---------
Co-authored-by: Giteabot <teabot@gitea.io>
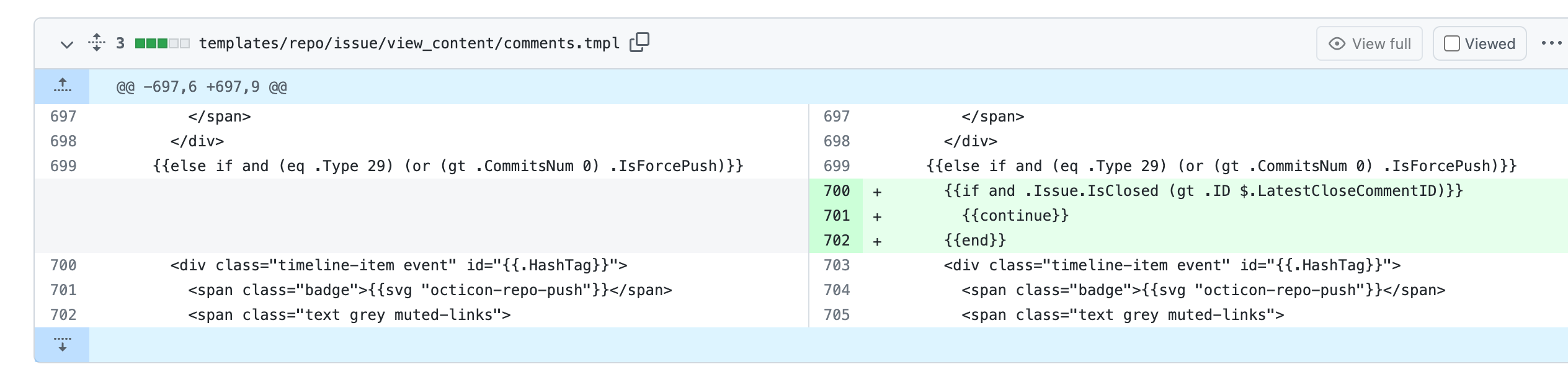
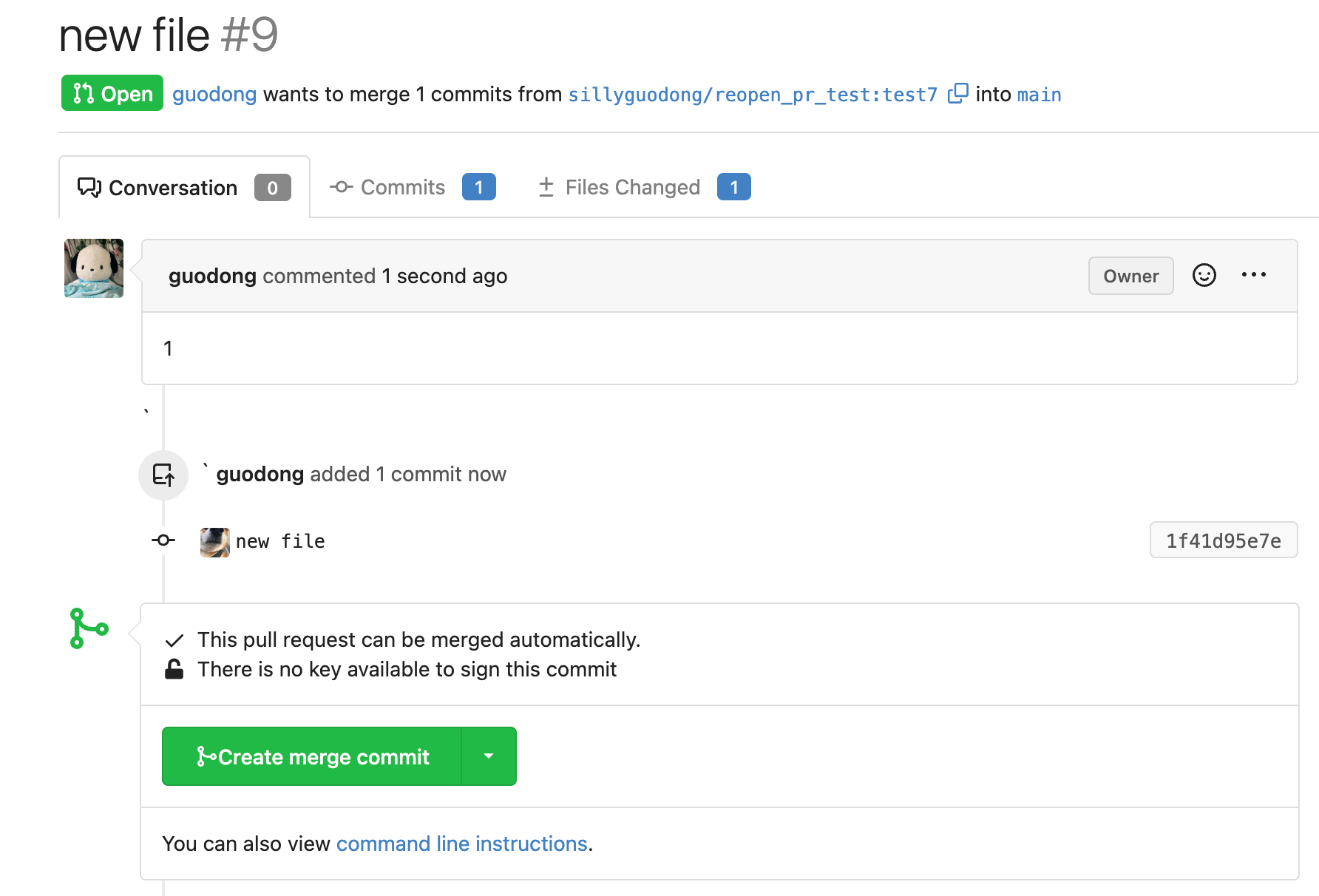
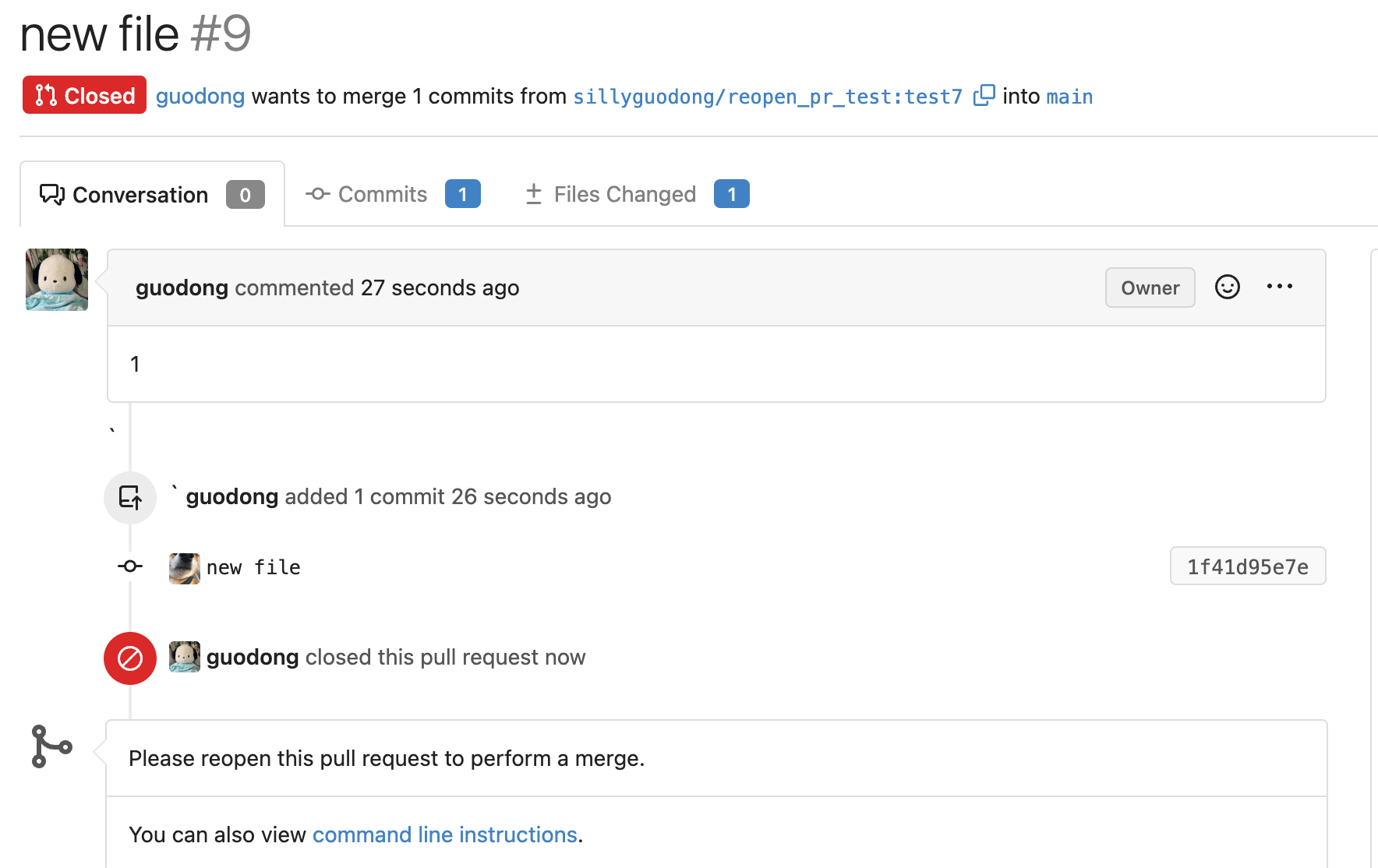
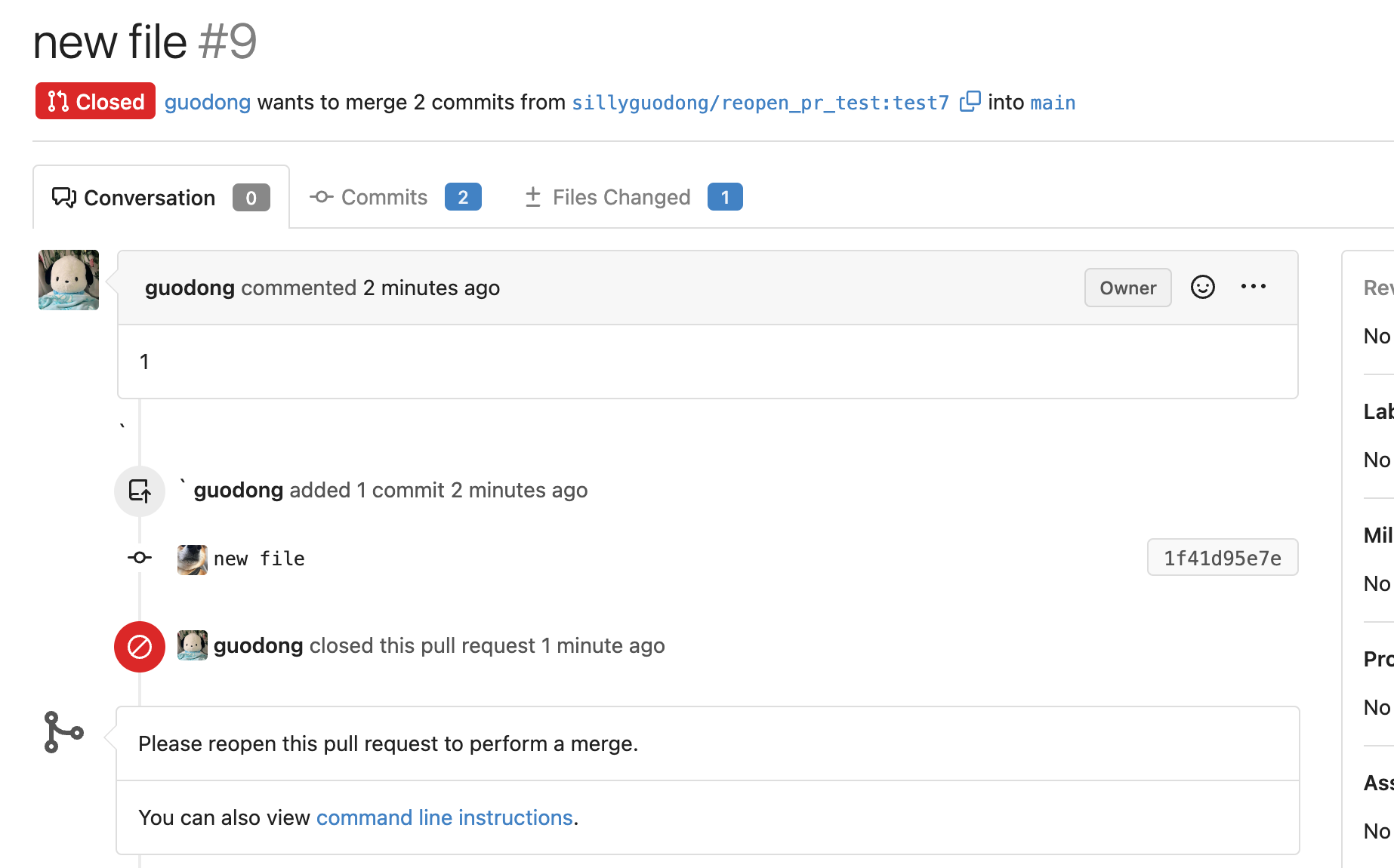
Close #24213
Replace #23830
#### Cause
- Before, in order to making PR can get latest commit after reopening,
the `ref`(${REPO_PATH}/refs/pull/${PR_INDEX}/head) of evrey closed PR
will be updated when pushing commits to the `head branch` of the closed
PR.
#### Changes
- For closed PR , won't perform these behavior: insert`comment`, push
`notification` (UI and email), exectue
[pushToBaseRepo](7422503341/services/pull/pull.go (L409))
function and trigger `action` any more when pushing to the `head branch`
of the closed PR.
- Refresh the reference of the PR when reopening the closed PR (**even
if the head branch has been deleted before**). Make the reference of PR
consistent with the `head branch`.
Close #24195
Some of the changes are taken from my another fix
f07b0de997
in #20147 (although that PR was discarded ....)
The bug is:
1. The old code doesn't handle `removedfile` event correctly
2. The old code doesn't provide attachments for type=CommentTypeReview
This PR doesn't intend to refactor the "upload" code to a perfect state
(to avoid making the review difficult), so some legacy styles are kept.
---------
Co-authored-by: silverwind <me@silverwind.io>
Co-authored-by: Giteabot <teabot@gitea.io>
Right now the authors search dropdown might take a long time to load if
amount of authors is huge.
Example: (In the video below, there are about 10000 authors, and it
takes about 10 seconds to open the author dropdown)
https://user-images.githubusercontent.com/17645053/229422229-98aa9656-3439-4f8c-9f4e-83bd8e2a2557.mov
Possible improvements can be made, which will take 2 steps (Thanks to
@wolfogre for advice):
Step 1:
Backend: Add a new api, which returns a limit of 30 posters with matched
prefix.
Frontend: Change the search behavior from frontend search(fomantic
search) to backend search(when input is changed, send a request to get
authors matching the current search prefix)
Step 2:
Backend: Optimize the api in step 1 using indexer to support fuzzy
search.
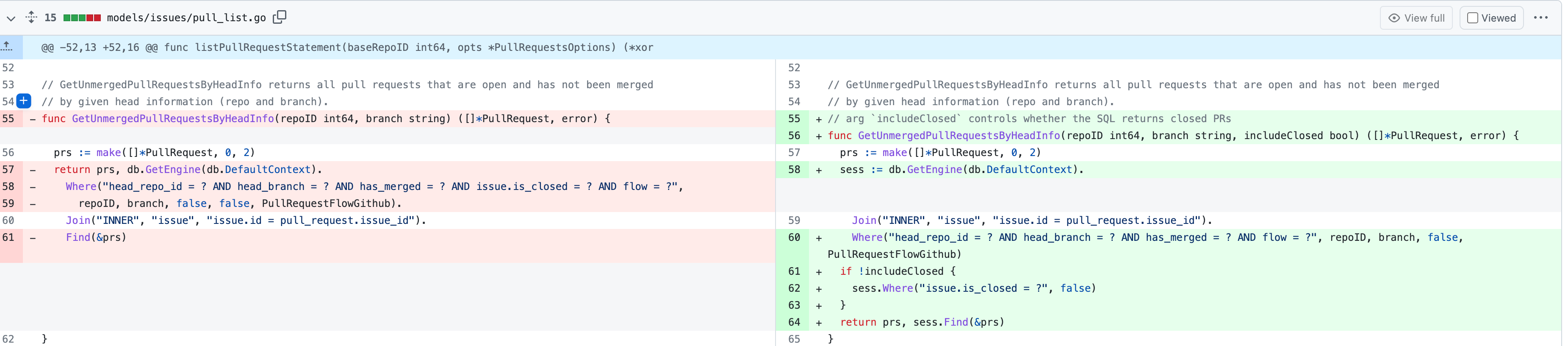
This PR is implements the first step. The main changes:
1. Added api: `GET /{type:issues|pulls}/posters` , which return a limit
of 30 users with matched prefix (prefix sent as query). If
`DEFAULT_SHOW_FULL_NAME` in `custom/conf/app.ini` is set to true, will
also include fullnames fuzzy search.
2. Added a tooltip saying "Shows a maximum of 30 users" to the author
search dropdown
3. Change the search behavior from frontend search to backend search
After:
https://user-images.githubusercontent.com/17645053/229430960-f88fafd8-fd5d-4f84-9df2-2677539d5d08.mov
Fixes: https://github.com/go-gitea/gitea/issues/22586
---------
Co-authored-by: wxiaoguang <wxiaoguang@gmail.com>
Co-authored-by: silverwind <me@silverwind.io>
Closes #20955
This PR adds the possibility to disable blank Issues, when the Repo has
templates. This can be done by creating the file
`.gitea/issue_config.yaml` with the content `blank_issues_enabled` in
the Repo.
Adds API endpoints to manage issue/PR dependencies
* `GET /repos/{owner}/{repo}/issues/{index}/blocks` List issues that are
blocked by this issue
* `POST /repos/{owner}/{repo}/issues/{index}/blocks` Block the issue
given in the body by the issue in path
* `DELETE /repos/{owner}/{repo}/issues/{index}/blocks` Unblock the issue
given in the body by the issue in path
* `GET /repos/{owner}/{repo}/issues/{index}/dependencies` List an
issue's dependencies
* `POST /repos/{owner}/{repo}/issues/{index}/dependencies` Create a new
issue dependencies
* `DELETE /repos/{owner}/{repo}/issues/{index}/dependencies` Remove an
issue dependency
Closes https://github.com/go-gitea/gitea/issues/15393
Closes #22115
Co-authored-by: Andrew Thornton <art27@cantab.net>
Before, the `dict "ctx" ...` map is used to pass data between templates.
Now, more and more templates need to use real Go context:
* #22962
* #23092
`ctx` is a Go concept for `Context`, misusing it may cause problems, and
it makes it difficult to review or refactor.
This PR contains 2 major changes:
* In the top scope of a template, the `$` is the same as the `.`, so the
old labels_sidebar's `root` is the `ctx`. So this `ctx` could just be
removed.
bd7f218dce
* Rename all other `ctx` to `ctxData`, and it perfectly matches how it
comes from backend: `"ctxData": ctx.Data`.
7c01260e1d
From now on, there is no `ctx` in templates. There are only:
* `ctxData` for passing data
* `Context` for Go context
GetActiveStopwatch & HasUserStopwatch is a hot piece of code that is
repeatedly called and on examination of the cpu profile for TestGit it
represents 0.44 seconds of CPU time. This PR reduces this time to 80ms.
---------
Signed-off-by: Andrew Thornton <art27@cantab.net>
Co-authored-by: KN4CK3R <admin@oldschoolhack.me>
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
Co-authored-by: delvh <leon@kske.dev>
This includes pull requests that you approved, requested changes or
commented on. Currently such pull requests are not visible in any of the
filters on /pulls, while they may need further action like merging, or
prodding the author or reviewers.
Especially when working with a large team on a repository it's helpful
to get a full overview of pull requests that may need your attention,
without having to sift through the complete list.
Add a new "exclusive" option per label. This makes it so that when the
label is named `scope/name`, no other label with the same `scope/`
prefix can be set on an issue.
The scope is determined by the last occurence of `/`, so for example
`scope/alpha/name` and `scope/beta/name` are considered to be in
different scopes and can coexist.
Exclusive scopes are not enforced by any database rules, however they
are enforced when editing labels at the models level, automatically
removing any existing labels in the same scope when either attaching a
new label or replacing all labels.
In menus use a circle instead of checkbox to indicate they function as
radio buttons per scope. Issue filtering by label ensures that only a
single scoped label is selected at a time. Clicking with alt key can be
used to remove a scoped label, both when editing individual issues and
batch editing.
Label rendering refactor for consistency and code simplification:
* Labels now consistently have the same shape, emojis and tooltips
everywhere. This includes the label list and label assignment menus.
* In label list, show description below label same as label menus.
* Don't use exactly black/white text colors to look a bit nicer.
* Simplify text color computation. There is no point computing luminance
in linear color space, as this is a perceptual problem and sRGB is
closer to perceptually linear.
* Increase height of label assignment menus to show more labels. Showing
only 3-4 labels at a time leads to a lot of scrolling.
* Render all labels with a new RenderLabel template helper function.
Label creation and editing in multiline modal menu:
* Change label creation to open a modal menu like label editing.
* Change menu layout to place name, description and colors on separate
lines.
* Don't color cancel button red in label editing modal menu.
* Align text to the left in model menu for better readability and
consistent with settings layout elsewhere.
Custom exclusive scoped label rendering:
* Display scoped label prefix and suffix with slightly darker and
lighter background color respectively, and a slanted edge between them
similar to the `/` symbol.
* In menus exclusive labels are grouped with a divider line.
---------
Co-authored-by: Yarden Shoham <hrsi88@gmail.com>
Co-authored-by: Lauris BH <lauris@nix.lv>
Fix #22797.
## Reason
If a comment was migrated from other platforms, this comment may have an
original author and its poster is always not the original author. When
the `roleDescriptor` func get the poster's role descriptor for a
comment, it does not check if the comment has an original author. So the
migrated comments' original authors might be marked as incorrect roles.
---------
Co-authored-by: zeripath <art27@cantab.net>
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
To avoid duplicated load of the same data in an HTTP request, we can set
a context cache to do that. i.e. Some pages may load a user from a
database with the same id in different areas on the same page. But the
code is hidden in two different deep logic. How should we share the
user? As a result of this PR, now if both entry functions accept
`context.Context` as the first parameter and we just need to refactor
`GetUserByID` to reuse the user from the context cache. Then it will not
be loaded twice on an HTTP request.
But of course, sometimes we would like to reload an object from the
database, that's why `RemoveContextData` is also exposed.
The core context cache is here. It defines a new context
```go
type cacheContext struct {
ctx context.Context
data map[any]map[any]any
lock sync.RWMutex
}
var cacheContextKey = struct{}{}
func WithCacheContext(ctx context.Context) context.Context {
return context.WithValue(ctx, cacheContextKey, &cacheContext{
ctx: ctx,
data: make(map[any]map[any]any),
})
}
```
Then you can use the below 4 methods to read/write/del the data within
the same context.
```go
func GetContextData(ctx context.Context, tp, key any) any
func SetContextData(ctx context.Context, tp, key, value any)
func RemoveContextData(ctx context.Context, tp, key any)
func GetWithContextCache[T any](ctx context.Context, cacheGroupKey string, cacheTargetID any, f func() (T, error)) (T, error)
```
Then let's take a look at how `system.GetString` implement it.
```go
func GetSetting(ctx context.Context, key string) (string, error) {
return cache.GetWithContextCache(ctx, contextCacheKey, key, func() (string, error) {
return cache.GetString(genSettingCacheKey(key), func() (string, error) {
res, err := GetSettingNoCache(ctx, key)
if err != nil {
return "", err
}
return res.SettingValue, nil
})
})
}
```
First, it will check if context data include the setting object with the
key. If not, it will query from the global cache which may be memory or
a Redis cache. If not, it will get the object from the database. In the
end, if the object gets from the global cache or database, it will be
set into the context cache.
An object stored in the context cache will only be destroyed after the
context disappeared.
In Go code, HTMLURL should be only used for external systems, like
API/webhook/mail/notification, etc.
If a URL is used by `Redirect` or rendered in a template, it should be a
relative URL (aka `Link()` in Gitea)
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
This PR fixes two problems. One is when filter repository issues, only
repository level projects are listed. Another is if you list open
issues, only open projects will be displayed in filter options and if
you list closed issues, only closed projects will be displayed in filter
options.
In this PR, both repository level and org/user level projects will be
displayed in filter, and both open and closed projects will be listed as
filter items.
---------
Co-authored-by: John Olheiser <john.olheiser@gmail.com>
Co-authored-by: zeripath <art27@cantab.net>
Co-authored-by: delvh <dev.lh@web.de>
Currently only a single project like milestone, not multiple like
labels.
Implements #14298
Code by @brechtvl
---------
Co-authored-by: Brecht Van Lommel <brecht@blender.org>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}