Fixes #27114.
* In Gitea 1.12 (#9532), a "dismiss stale approvals" branch protection
setting was introduced, for ignoring stale reviews when verifying the
approval count of a pull request.
* In Gitea 1.14 (#12674), the "dismiss review" feature was added.
* This caused confusion with users (#25858), as "dismiss" now means 2
different things.
* In Gitea 1.20 (#25882), the behavior of the "dismiss stale approvals"
branch protection was modified to actually dismiss the stale review.
For some users this new behavior of dismissing the stale reviews is not
desirable.
So this PR reintroduces the old behavior as a new "ignore stale
approvals" branch protection setting.
---------
Co-authored-by: delvh <dev.lh@web.de>
Fix #28157
This PR fix the possible bugs about actions schedule.
## The Changes
- Move `UpdateRepositoryUnit` and `SetRepoDefaultBranch` from models to
service layer
- Remove schedules plan from database and cancel waiting & running
schedules tasks in this repository when actions unit has been disabled
or global disabled.
- Remove schedules plan from database and cancel waiting & running
schedules tasks in this repository when default branch changed.
The 4 functions are duplicated, especially as interface methods. I think
we just need to keep `MustID` the only one and remove other 3.
```
MustID(b []byte) ObjectID
MustIDFromString(s string) ObjectID
NewID(b []byte) (ObjectID, error)
NewIDFromString(s string) (ObjectID, error)
```
Introduced the new interfrace method `ComputeHash` which will replace
the interface `HasherInterface`. Now we don't need to keep two
interfaces.
Reintroduced `git.NewIDFromString` and `git.MustIDFromString`. The new
function will detect the hash length to decide which objectformat of it.
If it's 40, then it's SHA1. If it's 64, then it's SHA256. This will be
right if the commitID is a full one. So the parameter should be always a
full commit id.
@AdamMajer Please review.
- Remove `ObjectFormatID`
- Remove function `ObjectFormatFromID`.
- Use `Sha1ObjectFormat` directly but not a pointer because it's an
empty struct.
- Store `ObjectFormatName` in `repository` struct
Refactor Hash interfaces and centralize hash function. This will allow
easier introduction of different hash function later on.
This forms the "no-op" part of the SHA256 enablement patch.
Fix #28056
This PR will check whether the repo has zero branch when pushing a
branch. If that, it means this repository hasn't been synced.
The reason caused that is after user upgrade from v1.20 -> v1.21, he
just push branches without visit the repository user interface. Because
all repositories routers will check whether a branches sync is necessary
but push has not such check.
For every repository, it has two states, synced or not synced. If there
is zero branch for a repository, then it will be assumed as non-sync
state. Otherwise, it's synced state. So if we think it's synced, we just
need to update branch/insert new branch. Otherwise do a full sync. So
that, for every push, there will be almost no extra load added. It's
high performance than yours.
For the implementation, we in fact will try to update the branch first,
if updated success with affect records > 0, then all are done. Because
that means the branch has been in the database. If no record is
affected, that means the branch does not exist in database. So there are
two possibilities. One is this is a new branch, then we just need to
insert the record. Another is the branches haven't been synced, then we
need to sync all the branches into database.
The function `GetByBean` has an obvious defect that when the fields are
empty values, it will be ignored. Then users will get a wrong result
which is possibly used to make a security problem.
To avoid the possibility, this PR removed function `GetByBean` and all
references.
And some new generic functions have been introduced to be used.
The recommand usage like below.
```go
// if query an object according id
obj, err := db.GetByID[Object](ctx, id)
// query with other conditions
obj, err := db.Get[Object](ctx, builder.Eq{"a": a, "b":b})
```
Part of #27065
This PR touches functions used in templates. As templates are not static
typed, errors are harder to find, but I hope I catch it all. I think
some tests from other persons do not hurt.
This PR removed `unittest.MainTest` the second parameter
`TestOptions.GiteaRoot`. Now it detects the root directory by current
working directory.
---------
Co-authored-by: wxiaoguang <wxiaoguang@gmail.com>
Related to #26239
This PR makes some fixes:
- do not show the prompt for mirror repos and repos with pull request
units disabled
- use `commit_time` instead of `updated_unix`, as `commit_time` is the
real time when the branch was pushed
In the original implementation, we can only get the first 30 records of
the commit status (the default paging size), if the commit status is
more than 30, it will lead to the bug #25990. I made the following two
changes.
- On the page, use the ` db.ListOptions{ListAll: true}` parameter
instead of `db.ListOptions{}`
- The `GetLatestCommitStatus` function makes a determination as to
whether or not a pager is being used.
fixed #25990
This PR
- Fix #26093. Replace `time.Time` with `timeutil.TimeStamp`
- Fix #26135. Add missing `xorm:"extends"` to `CountLFSMetaObject` for
LFS meta object query
- Add a unit test for LFS meta object garbage collection
Before:

After:
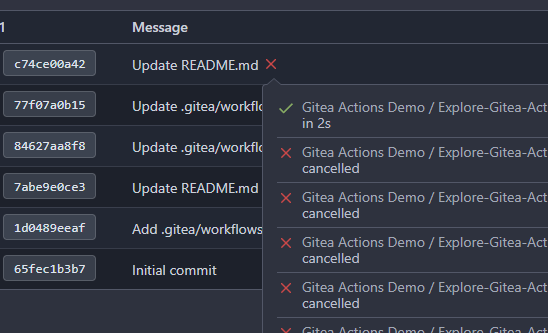
There's a bug in the recent logic, `CalcCommitStatus` will always return
the first item of `statuses` or error status, because `state` is defined
with default value which should be `CommitStatusSuccess`
Then
``` golang
if status.State.NoBetterThan(state) {
```
this `if` will always return false unless `status.State =
CommitStatusError` which makes no sense.
So `lastStatus` will always be `nil` or error status.
Then we will always return the first item of `statuses` here or only
return error status, and this is why in the first picture the commit
status is `Success` but not `Failure`.
af1ffbcd63/models/git/commit_status.go (L204-L211)
Co-authored-by: Giteabot <teabot@gitea.io>
Fix #25776. Close #25826.
In the discussion of #25776, @wolfogre's suggestion was to remove the
commit status of `running` and `warning` to keep it consistent with
github.
references:
-
https://docs.github.com/en/rest/commits/statuses?apiVersion=2022-11-28#about-commit-statuses
## ⚠️ BREAKING ⚠️
So the commit status of Gitea will be consistent with GitHub, only
`pending`, `success`, `error` and `failure`, while `warning` and
`running` are not supported anymore.
---------
Co-authored-by: Jason Song <i@wolfogre.com>
This PR will display a pull request creation hint on the repository home
page when there are newly created branches with no pull request. Only
the recent 6 hours and 2 updated branches will be displayed.
Inspired by #14003
Replace #14003
Resolves #311
Resolves #13196
Resolves #23743
co-authored by @kolaente
When branch's commit CommitMessage is too long, the column maybe too
short.(TEXT 16K for mysql).
This PR will fix it to only store the summary because these message will
only show on branch list or possible future search?
Related #14180
Related #25233
Related #22639
Close #19786
Related #12763
This PR will change all the branches retrieve method from reading git
data to read database to reduce git read operations.
- [x] Sync git branches information into database when push git data
- [x] Create a new table `Branch`, merge some columns of `DeletedBranch`
into `Branch` table and drop the table `DeletedBranch`.
- [x] Read `Branch` table when visit `code` -> `branch` page
- [x] Read `Branch` table when list branch names in `code` page dropdown
- [x] Read `Branch` table when list git ref compare page
- [x] Provide a button in admin page to manually sync all branches.
- [x] Sync branches if repository is not empty but database branches are
empty when visiting pages with branches list
- [x] Use `commit_time desc` as the default FindBranch order by to keep
consistent as before and deleted branches will be always at the end.
---------
Co-authored-by: Jason Song <i@wolfogre.com>
Since #23493 has conflicts with latest commits, this PR is my proposal
for fixing #23371
Details are in the comments
And refactor the `modules/options` module, to make it always use
"filepath" to access local files.
Benefits:
* No need to do `util.CleanPath(strings.ReplaceAll(p, "\\", "/"))),
"/")` any more (not only one before)
* The function behaviors are clearly defined
Replace #23350.
Refactor `setting.Database.UseMySQL` to
`setting.Database.Type.IsMySQL()`.
To avoid mismatching between `Type` and `UseXXX`.
This refactor can fix the bug mentioned in #23350, so it should be
backported.
To avoid duplicated load of the same data in an HTTP request, we can set
a context cache to do that. i.e. Some pages may load a user from a
database with the same id in different areas on the same page. But the
code is hidden in two different deep logic. How should we share the
user? As a result of this PR, now if both entry functions accept
`context.Context` as the first parameter and we just need to refactor
`GetUserByID` to reuse the user from the context cache. Then it will not
be loaded twice on an HTTP request.
But of course, sometimes we would like to reload an object from the
database, that's why `RemoveContextData` is also exposed.
The core context cache is here. It defines a new context
```go
type cacheContext struct {
ctx context.Context
data map[any]map[any]any
lock sync.RWMutex
}
var cacheContextKey = struct{}{}
func WithCacheContext(ctx context.Context) context.Context {
return context.WithValue(ctx, cacheContextKey, &cacheContext{
ctx: ctx,
data: make(map[any]map[any]any),
})
}
```
Then you can use the below 4 methods to read/write/del the data within
the same context.
```go
func GetContextData(ctx context.Context, tp, key any) any
func SetContextData(ctx context.Context, tp, key, value any)
func RemoveContextData(ctx context.Context, tp, key any)
func GetWithContextCache[T any](ctx context.Context, cacheGroupKey string, cacheTargetID any, f func() (T, error)) (T, error)
```
Then let's take a look at how `system.GetString` implement it.
```go
func GetSetting(ctx context.Context, key string) (string, error) {
return cache.GetWithContextCache(ctx, contextCacheKey, key, func() (string, error) {
return cache.GetString(genSettingCacheKey(key), func() (string, error) {
res, err := GetSettingNoCache(ctx, key)
if err != nil {
return "", err
}
return res.SettingValue, nil
})
})
}
```
First, it will check if context data include the setting object with the
key. If not, it will query from the global cache which may be memory or
a Redis cache. If not, it will get the object from the database. In the
end, if the object gets from the global cache or database, it will be
set into the context cache.
An object stored in the context cache will only be destroyed after the
context disappeared.
This PR adds a task to the cron service to allow garbage collection of
LFS meta objects. As repositories may have a large number of
LFSMetaObjects, an updated column is added to this table and it is used
to perform a generational GC to attempt to reduce the amount of work.
(There may need to be a bit more work here but this is probably enough
for the moment.)
Fix #7045
Signed-off-by: Andrew Thornton <art27@cantab.net>