This PR adds a new table named commit status summary to reduce queries
from the commit status table. After this change, commit status summary
table will be used for the final result, commit status table will be for
details.
---------
Co-authored-by: Jason Song <i@wolfogre.com>
This PR replaces the use of `max( id )`, and instead using ``max(
`index` )`` for determining the latest commit status. Building business
logic over an `auto_increment` primary key like `id` is risky and
there’re already plenty of discussions on the Internet.
There‘s no guarantee for `auto_increment` values to be monotonic,
especially upon failures or with a cluster. In the specific case, we met
the problem of commit statuses being outdated when using TiDB as the
database. As [being
documented](https://docs.pingcap.com/tidb/stable/auto-increment),
`auto_increment` values assigned to an `insert` statement will only be
monotonic on a per server (node) basis.
Closes #30074.
(cherry picked from commit 7443a10fc3d722d3326a0cb7b15b208f907c72d7)
Clarify when "string" should be used (and be escaped), and when
"template.HTML" should be used (no need to escape)
And help PRs like #29059 , to render the error messages correctly.
(cherry picked from commit f3eb835886031df7a562abc123c3f6011c81eca8)
Conflicts:
modules/web/middleware/binding.go
routers/web/feed/convert.go
tests/integration/branches_test.go
tests/integration/repo_branch_test.go
trivial context conflicts
The 4 functions are duplicated, especially as interface methods. I think
we just need to keep `MustID` the only one and remove other 3.
```
MustID(b []byte) ObjectID
MustIDFromString(s string) ObjectID
NewID(b []byte) (ObjectID, error)
NewIDFromString(s string) (ObjectID, error)
```
Introduced the new interfrace method `ComputeHash` which will replace
the interface `HasherInterface`. Now we don't need to keep two
interfaces.
Reintroduced `git.NewIDFromString` and `git.MustIDFromString`. The new
function will detect the hash length to decide which objectformat of it.
If it's 40, then it's SHA1. If it's 64, then it's SHA256. This will be
right if the commitID is a full one. So the parameter should be always a
full commit id.
@AdamMajer Please review.
Refactor Hash interfaces and centralize hash function. This will allow
easier introduction of different hash function later on.
This forms the "no-op" part of the SHA256 enablement patch.
Part of #27065
This PR touches functions used in templates. As templates are not static
typed, errors are harder to find, but I hope I catch it all. I think
some tests from other persons do not hurt.
In the original implementation, we can only get the first 30 records of
the commit status (the default paging size), if the commit status is
more than 30, it will lead to the bug #25990. I made the following two
changes.
- On the page, use the ` db.ListOptions{ListAll: true}` parameter
instead of `db.ListOptions{}`
- The `GetLatestCommitStatus` function makes a determination as to
whether or not a pager is being used.
fixed #25990
Before:

After:
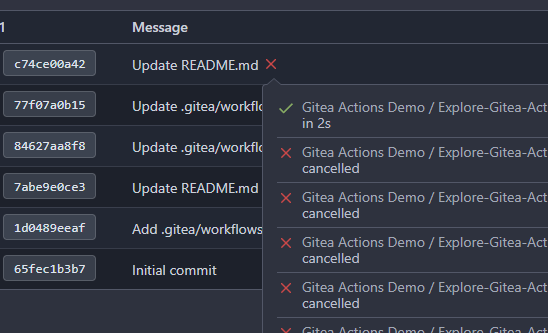
There's a bug in the recent logic, `CalcCommitStatus` will always return
the first item of `statuses` or error status, because `state` is defined
with default value which should be `CommitStatusSuccess`
Then
``` golang
if status.State.NoBetterThan(state) {
```
this `if` will always return false unless `status.State =
CommitStatusError` which makes no sense.
So `lastStatus` will always be `nil` or error status.
Then we will always return the first item of `statuses` here or only
return error status, and this is why in the first picture the commit
status is `Success` but not `Failure`.
af1ffbcd63/models/git/commit_status.go (L204-L211)
Co-authored-by: Giteabot <teabot@gitea.io>
Replace #23350.
Refactor `setting.Database.UseMySQL` to
`setting.Database.Type.IsMySQL()`.
To avoid mismatching between `Type` and `UseXXX`.
This refactor can fix the bug mentioned in #23350, so it should be
backported.
To avoid duplicated load of the same data in an HTTP request, we can set
a context cache to do that. i.e. Some pages may load a user from a
database with the same id in different areas on the same page. But the
code is hidden in two different deep logic. How should we share the
user? As a result of this PR, now if both entry functions accept
`context.Context` as the first parameter and we just need to refactor
`GetUserByID` to reuse the user from the context cache. Then it will not
be loaded twice on an HTTP request.
But of course, sometimes we would like to reload an object from the
database, that's why `RemoveContextData` is also exposed.
The core context cache is here. It defines a new context
```go
type cacheContext struct {
ctx context.Context
data map[any]map[any]any
lock sync.RWMutex
}
var cacheContextKey = struct{}{}
func WithCacheContext(ctx context.Context) context.Context {
return context.WithValue(ctx, cacheContextKey, &cacheContext{
ctx: ctx,
data: make(map[any]map[any]any),
})
}
```
Then you can use the below 4 methods to read/write/del the data within
the same context.
```go
func GetContextData(ctx context.Context, tp, key any) any
func SetContextData(ctx context.Context, tp, key, value any)
func RemoveContextData(ctx context.Context, tp, key any)
func GetWithContextCache[T any](ctx context.Context, cacheGroupKey string, cacheTargetID any, f func() (T, error)) (T, error)
```
Then let's take a look at how `system.GetString` implement it.
```go
func GetSetting(ctx context.Context, key string) (string, error) {
return cache.GetWithContextCache(ctx, contextCacheKey, key, func() (string, error) {
return cache.GetString(genSettingCacheKey(key), func() (string, error) {
res, err := GetSettingNoCache(ctx, key)
if err != nil {
return "", err
}
return res.SettingValue, nil
})
})
}
```
First, it will check if context data include the setting object with the
key. If not, it will query from the global cache which may be memory or
a Redis cache. If not, it will get the object from the database. In the
end, if the object gets from the global cache or database, it will be
set into the context cache.
An object stored in the context cache will only be destroyed after the
context disappeared.
After #22362, we can feel free to use transactions without
`db.DefaultContext`.
And there are still lots of models using `db.DefaultContext`, I think we
should refactor them carefully and one by one.
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
Change all license headers to comply with REUSE specification.
Fix #16132
Co-authored-by: flynnnnnnnnnn <flynnnnnnnnnn@github>
Co-authored-by: John Olheiser <john.olheiser@gmail.com>
Fix #19513
This PR introduce a new db method `InTransaction(context.Context)`,
and also builtin check on `db.TxContext` and `db.WithTx`.
There is also a new method `db.AutoTx` has been introduced but could be used by other PRs.
`WithTx` will always open a new transaction, if a transaction exist in context, return an error.
`AutoTx` will try to open a new transaction if no transaction exist in context.
That means it will always enter a transaction if there is no error.
Co-authored-by: delvh <dev.lh@web.de>
Co-authored-by: 6543 <6543@obermui.de>
* Move access and repo permission to models/perm/access
* fix test
* Move some git related files into sub package models/git
* Fix build
* fix git test
* move lfs to sub package
* move more git related functions to models/git
* Move functions sequence
* Some improvements per @KN4CK3R and @delvh