Close #14601
Fix #3690
Revive of #14601.
Updated to current code, cleanup and added more read/write checks.
Signed-off-by: Andrew Thornton <art27@cantab.net>
Signed-off-by: Andre Bruch <ab@andrebruch.com>
Co-authored-by: zeripath <art27@cantab.net>
Co-authored-by: 6543 <6543@obermui.de>
Co-authored-by: Norwin <git@nroo.de>
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
Change all license headers to comply with REUSE specification.
Fix #16132
Co-authored-by: flynnnnnnnnnn <flynnnnnnnnnn@github>
Co-authored-by: John Olheiser <john.olheiser@gmail.com>
If a deleted-branch has already been restored, a request to restore it
again will cause a NPE. This PR adds detection for this case, but also
disables buttons when they're clicked in order to help prevent
accidental repeat requests.
Fix #21930
Signed-off-by: Andrew Thornton <art27@cantab.net>
Fix #20456
At some point during the 1.17 cycle abbreviated refishs to issue
branches started breaking. This is likely due serious inconsistencies in
our management of refs throughout Gitea - which is a bug needing to be
addressed in a different PR. (Likely more than one)
We should try to use non-abbreviated `fullref`s as much as possible.
That is where a user has inputted a abbreviated `refish` we should add
`refs/heads/` if it is `branch` etc. I know people keep writing and
merging PRs that remove prefixes from stored content but it is just
wrong and it keeps causing problems like this. We should only remove the
prefix at the time of
presentation as the prefix is the only way of knowing umambiguously and
permanently if the `ref` is referring to a `branch`, `tag` or `commit` /
`SHA`. We need to make it so that every ref has the appropriate prefix,
and probably also need to come up with some definitely unambiguous way
of storing `SHA`s if they're used in a `ref` or `refish` field. We must
not store a potentially
ambiguous `refish` as a `ref`. (Especially when referring a `tag` -
there is no reason why users cannot create a `branch` with the same
short name as a `tag` and vice versa and any attempt to prevent this
will fail. You can even create a `branch` and a
`tag` that matches the `SHA` pattern.)
To that end in order to fix this bug, when parsing issue templates check
the provided `Ref` (here a `refish` because almost all users do not know
or understand the subtly), if it does not start with `refs/` add the
`BranchPrefix` to it. This allows people to make their templates refer
to a `tag` but not to a `SHA` directly. (I don't think that is
particularly unreasonable but if people disagree I can make the `refish`
be checked to see if it matches the `SHA` pattern.)
Next we need to handle the issue links that are already written. The
links here are created with `git.RefURL`
Here we see there is a bug introduced in #17551 whereby the provided
`ref` argument can be double-escaped so we remove the incorrect external
escape. (The escape added in #17551 is in the right place -
unfortunately I missed that the calling function was doing the wrong
thing.)
Then within `RefURL()` we check if an unprefixed `ref` (therefore
potentially a `refish`) matches the `SHA` pattern before assuming that
is actually a `commit` - otherwise is assumed to be a `branch`. This
will handle most of the problem cases excepting the very unusual cases
where someone has deliberately written a `branch` to look like a `SHA1`.
But please if something is called a `ref` or interpreted as a `ref` make
it a full-ref before storing or using it. By all means if something is a
`branch` assume the prefix is removed but always add it back in if you
are using it as a `ref`. Stop storing abbreviated `branch` names and
`tag` names - which are `refish` as a `ref`. It will keep on causing
problems like this.
Fix #20456
Signed-off-by: Andrew Thornton <art27@cantab.net>
Co-authored-by: Lauris BH <lauris@nix.lv>
Co-authored-by: wxiaoguang <wxiaoguang@gmail.com>
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
This patch provide a mechanism to disable RSS/Atom feed.
Signed-off-by: Xinyu Zhou <i@sourcehut.net>
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
Co-authored-by: 6543 <6543@obermui.de>
This PR adds a context parameter to a bunch of methods. Some helper
`xxxCtx()` methods got replaced with the normal name now.
Co-authored-by: delvh <dev.lh@web.de>
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
The doctor check `storages` currently only checks the attachment
storage. This PR adds some basic garbage collection functionality for
the other types of storage.
Signed-off-by: Andrew Thornton <art27@cantab.net>
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
_This is a different approach to #20267, I took the liberty of adapting
some parts, see below_
## Context
In some cases, a weebhook endpoint requires some kind of authentication.
The usual way is by sending a static `Authorization` header, with a
given token. For instance:
- Matrix expects a `Bearer <token>` (already implemented, by storing the
header cleartext in the metadata - which is buggy on retry #19872)
- TeamCity #18667
- Gitea instances #20267
- SourceHut https://man.sr.ht/graphql.md#authentication-strategies (this
is my actual personal need :)
## Proposed solution
Add a dedicated encrypt column to the webhook table (instead of storing
it as meta as proposed in #20267), so that it gets available for all
present and future hook types (especially the custom ones #19307).
This would also solve the buggy matrix retry #19872.
As a first step, I would recommend focusing on the backend logic and
improve the frontend at a later stage. For now the UI is a simple
`Authorization` field (which could be later customized with `Bearer` and
`Basic` switches):
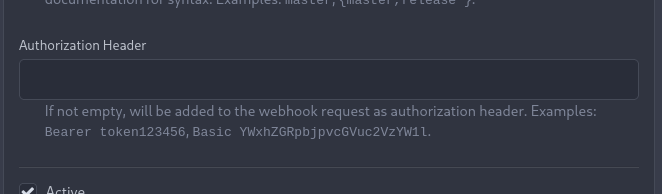
The header name is hard-coded, since I couldn't fine any usecase
justifying otherwise.
## Questions
- What do you think of this approach? @justusbunsi @Gusted @silverwind
- ~~How are the migrations generated? Do I have to manually create a new
file, or is there a command for that?~~
- ~~I started adding it to the API: should I complete it or should I
drop it? (I don't know how much the API is actually used)~~
## Done as well:
- add a migration for the existing matrix webhooks and remove the
`Authorization` logic there
_Closes #19872_
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
Co-authored-by: Gusted <williamzijl7@hotmail.com>
Co-authored-by: delvh <dev.lh@web.de>
I found myself wondering whether a PR I scheduled for automerge was
actually merged. It was, but I didn't receive a mail notification for it
- that makes sense considering I am the doer and usually don't want to
receive such notifications. But ideally I want to receive a notification
when a PR was merged because I scheduled it for automerge.
This PR implements exactly that.
The implementation works, but I wonder if there's a way to avoid passing
the "This PR was automerged" state down so much. I tried solving this
via the database (checking if there's an automerge scheduled for this PR
when sending the notification) but that did not work reliably, probably
because sending the notification happens async and the entry might have
already been deleted. My implementation might be the most
straightforward but maybe not the most elegant.
Signed-off-by: Andrew Thornton <art27@cantab.net>
Co-authored-by: Lauris BH <lauris@nix.lv>
Co-authored-by: Andrew Thornton <art27@cantab.net>
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
This stype name is also used in many repos, example:
[``README_ZH.md``](https://github.com/go-gitea/gitea/blob/main/README_ZH.md)
Signed-off-by: a1012112796 <1012112796@qq.com>
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
Co-authored-by: zeripath <art27@cantab.net>
At the moment a repository reference is needed for webhooks. With the
upcoming package PR we need to send webhooks without a repository
reference. For example a package is uploaded to an organization. In
theory this enables the usage of webhooks for future user actions.
This PR removes the repository id from `HookTask` and changes how the
hooks are processed (see `services/webhook/deliver.go`). In a follow up
PR I want to remove the usage of the `UniqueQueue´ and replace it with a
normal queue because there is no reason to be unique.
Co-authored-by: 6543 <6543@obermui.de>
Fixes #21379
The commits are capped by `setting.UI.FeedMaxCommitNum` so
`len(commits)` is not the correct number. So this PR adds a new
`TotalCommits` field.
Co-authored-by: wxiaoguang <wxiaoguang@gmail.com>
Close #20315 (fix the panic when parsing invalid input), Speed up #20231 (use ls-tree without size field)
Introduce ListEntriesRecursiveFast (ls-tree without size) and ListEntriesRecursiveWithSize (ls-tree with size)
Fixes #21184
Regression of #19552
Instead of using `GetBlobByPath` I use the already existing instances.
We need more information from #19530 if that error is still present.
If you are create a new new branch while viewing file or directory, you
get redirected to the root of the repo. With this PR, you keep your
current path instead of getting redirected to the repo root.
In #21088 I accidentally forgot to support multiple branches. It always
checks the default branch, no matter on which branch you are working on.
With this fix, it always shows the error from the current branch. Sorry
for that.
Add support for triggering webhook notifications on wiki changes.
This PR contains frontend and backend for webhook notifications on wiki actions (create a new page, rename a page, edit a page and delete a page). The frontend got a new checkbox under the Custom Event -> Repository Events section. There is only one checkbox for create/edit/rename/delete actions, because it makes no sense to separate it and others like releases or packages follow the same schema.
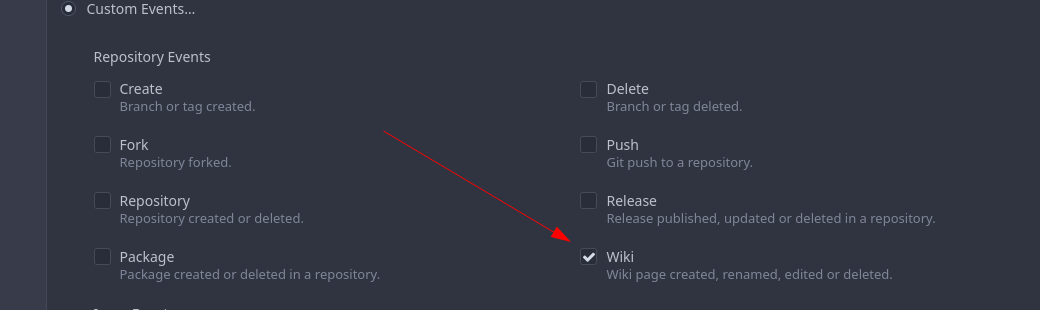
The actions itself are separated, so that different notifications will be executed (with the "action" field). All the webhook receivers implement the new interface method (Wiki) and the corresponding tests.
When implementing this, I encounter a little bug on editing a wiki page. Creating and editing a wiki page is technically the same action and will be handled by the ```updateWikiPage``` function. But the function need to know if it is a new wiki page or just a change. This distinction is done by the ```action``` parameter, but this will not be sent by the frontend (on form submit). This PR will fix this by adding the ```action``` parameter with the values ```_new``` or ```_edit```, which will be used by the ```updateWikiPage``` function.
I've done integration tests with matrix and gitea (http).
Fix #16457
Signed-off-by: Aaron Fischer <mail@aaron-fischer.net>
A testing cleanup.
This pull request replaces `os.MkdirTemp` with `t.TempDir`. We can use the `T.TempDir` function from the `testing` package to create temporary directory. The directory created by `T.TempDir` is automatically removed when the test and all its subtests complete.
This saves us at least 2 lines (error check, and cleanup) on every instance, or in some cases adds cleanup that we forgot.
Reference: https://pkg.go.dev/testing#T.TempDir
```go
func TestFoo(t *testing.T) {
// before
tmpDir, err := os.MkdirTemp("", "")
require.NoError(t, err)
defer os.RemoveAll(tmpDir)
// now
tmpDir := t.TempDir()
}
```
Signed-off-by: Eng Zer Jun <engzerjun@gmail.com>
The webhook payload should use the right ref when it‘s specified in the testing request.
The compare URL should not be empty, a URL like `compare/A...A` seems useless in most cases but is helpful when testing.
* feat: extend issue template for yaml
* feat: support yaml template
* feat: render form to markdown
* feat: support yaml template for pr
* chore: rename to Fields
* feat: template unmarshal
* feat: split template
* feat: render to markdown
* feat: use full name as template file name
* chore: remove useless file
* feat: use dropdown of fomantic ui
* feat: update input style
* docs: more comments
* fix: render text without render
* chore: fix lint error
* fix: support use description as about in markdown
* fix: add field class in form
* chore: generate swagger
* feat: validate template
* feat: support is_nummber and regex
* test: fix broken unit tests
* fix: ignore empty body of md template
* fix: make multiple easymde editors work in one page
* feat: better UI
* fix: js error in pr form
* chore: generate swagger
* feat: support regex validation
* chore: generate swagger
* fix: refresh each markdown editor
* chore: give up required validation
* fix: correct issue template candidates
* fix: correct checkboxes style
* chore: ignore .hugo_build.lock in docs
* docs: separate out a new doc for merge templates
* docs: introduce syntax of yaml template
* feat: show a alert for invalid templates
* test: add case for a valid template
* fix: correct attributes of required checkbox
* fix: add class not-under-easymde for dropzone
* fix: use more back-quotes
* chore: remove translation in zh-CN
* fix EasyMDE statusbar margin
* fix: remove repeated blocks
* fix: reuse regex for quotes
Co-authored-by: wxiaoguang <wxiaoguang@gmail.com>
* fix hard-coded timeout and error panic in API archive download endpoint
This commit updates the `GET /api/v1/repos/{owner}/{repo}/archive/{archive}`
endpoint which prior to this PR had a couple of issues.
1. The endpoint had a hard-coded 20s timeout for the archiver to complete after
which a 500 (Internal Server Error) was returned to client. For a scripted
API client there was no clear way of telling that the operation timed out and
that it should retry.
2. Whenever the timeout _did occur_, the code used to panic. This was caused by
the API endpoint "delegating" to the same call path as the web, which uses a
slightly different way of reporting errors (HTML rather than JSON for
example).
More specifically, `api/v1/repo/file.go#GetArchive` just called through to
`web/repo/repo.go#Download`, which expects the `Context` to have a `Render`
field set, but which is `nil` for API calls. Hence, a `nil` pointer error.
The code addresses (1) by dropping the hard-coded timeout. Instead, any
timeout/cancelation on the incoming `Context` is used.
The code addresses (2) by updating the API endpoint to use a separate call path
for the API-triggered archive download. This avoids producing HTML-errors on
errors (it now produces JSON errors).
Signed-off-by: Peter Gardfjäll <peter.gardfjall.work@gmail.com>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}