171 lines
18 KiB
Markdown
171 lines
18 KiB
Markdown
|
|
---
|
||
|
|
status: proposed
|
||
|
|
creation-date: "2023-04-13"
|
||
|
|
authors: [ "@andrewn" ]
|
||
|
|
coach: "@grzesiek"
|
||
|
|
---
|
||
|
|
|
||
|
|
# GitLab Service-Integration: AI and Beyond
|
||
|
|
|
||
|
|
This document is an abbreviated proposal for Service-Integration to allow teams within GitLab to rapidly build new application features that leverage AI, ML, and data technologies.
|
||
|
|
|
||
|
|
## Executive Summary
|
||
|
|
|
||
|
|
This document proposes a service-integration approach to setting up infrastructure to allow teams within GitLab to build new application features that leverage AI, ML, and data technologies at a rapid pace. The scope of the document is limited specifically to internally hosted features, not third-party APIs. The current application architecture runs most GitLab application features in Ruby. However, many ML/AI experiments require different resources and tools, implemented in different languages, with huge libraries that do not always play nicely together, and have different hardware requirements. Adding all these features to the existing infrastructure will increase the size of the GitLab application container rapidly, resulting in slower startup times, increased number of dependencies, security risks, negatively impacting development velocity, and increasing complexity due to different hardware requirements. As an alternative, the proposal suggests adding services to avoid overloading GitLabs main workloads. These services will run independently with isolated resources and dependencies. By adding services, GitLab can maintain the availability and security of GitLab.com, and enable engineers to rapidly iterate on new ML/AI experiments.
|
||
|
|
|
||
|
|
## Scope
|
||
|
|
|
||
|
|
The infrastructure, platform, and other changes related to ML/AI experiments is broad. This blueprint is limited specifically to the following scope:
|
||
|
|
|
||
|
|
1. Production workloads, running (directly or indirectly) as a result of requests into the GitLab application (`gitlab.com`), or an associated subdomains (for example, `codesuggestions.gitlab.com`).
|
||
|
|
1. Excludes requests from the GitLab application, made to third-party APIs outside of our infrastructure. From an Infrastructure point-of-view, external AI/ML API requests are no different from other API (non ML/AI) requests and generally follow the existing guidelines that are in place for calling external APIs.
|
||
|
|
1. Excludes training and tuning workloads not _directly_ connected to our production workloads. Training and tuning workloads are distinct from production workloads and will be covered by their own blueprint(s).
|
||
|
|
|
||
|
|
## Running Production ML/AI experiment workloads
|
||
|
|
|
||
|
|
### Why Not Simply Continue To Use The Existing Application Architecture?
|
||
|
|
|
||
|
|
Let's start with some background on how the application is deployed:
|
||
|
|
|
||
|
|
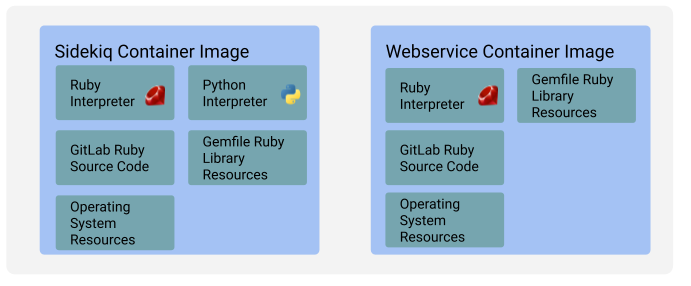
1. Most GitLab application features are implemented in Ruby and run in one of two types of Ruby deployments: broadly Rails and Sidekiq (although we do partition this traffic further for different workloads).
|
||
|
|
1. These Ruby workloads have two main container images `gitlab-webservice-ee` and `gitlab-sidekiq-ee`. All the code, libraries, binaries, and other resources that we use to support the main Ruby part of the codebase are embedded within these images.
|
||
|
|
1. There are thousands of pods running these containers in production for GitLab.com at any moment in time. They are started up and shut down at a high rate throughout the day as traffic demands on the site fluctuate.
|
||
|
|
1. For _most_ new features developed, any new supporting resources need to be added to either one, or both of these containers.
|
||
|
|
|
||
|
|
\
|
||
|
|
[source](https://docs.google.com/drawings/d/1RiTUnsDSkTGaMqK_RfUlCd_rQ6CgSInhfQJNewIKf1M/edit)
|
||
|
|
|
||
|
|
Many of the initial discussions focus on adding supporting resources to these existing containers ([example](https://gitlab.com/gitlab-org/gitlab/-/issues/403630#note_1345192671)). Choosing this approach would have many downsides, in terms of both the velocity at which new features can be iterated on, and in terms of the availability of GitLab.com.
|
||
|
|
|
||
|
|
Many of the AI experiments that GitLab is considering integrating into the application are substantially different from other libraries and tools that have been integrated in the past.
|
||
|
|
|
||
|
|
1. ML toolkits are **implemented in a plethora of languages**, each requiring separate runtimes. Python, C, C++ are the most common, but there is a long tail of languages used.
|
||
|
|
1. There are a very large number of tools that we're looking to integrate with and **no single tool will support all the features that are being investigated**. Tensorflow, PyTorch, Keras, Scikit-learn, Alpaca are just a few examples.
|
||
|
|
1. **These libraries are huge**. Tensorflow's container image with GPU support is 3GB, PyTorch is 5GB, Keras is 300MB. Prophet is ~250MB.
|
||
|
|
1. Many of these **libraries do not play nicely together**: they may have dependencies that are not compatible, or require different versions of Python, or GPU driver versions.
|
||
|
|
|
||
|
|
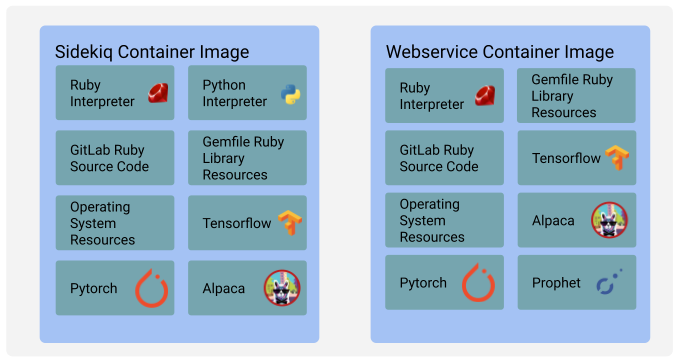
It's likely that in the next few months, GitLab will experiment with many different features, using many different libraries.
|
||
|
|
|
||
|
|
Trying to deploy all of these features into the existing infrastructure would have many downsides:
|
||
|
|
|
||
|
|
1. **The size of the GitLab application container would expand very rapidly** as each new experiment introduces a new set of supporting libraries, each library is as big, or bigger, than the existing GitLab application within the container.
|
||
|
|
1. **Startup times for new workloads would increase**, potentially impacting the availability of GitLab.com during high-traffic periods.
|
||
|
|
1. The number of dependencies within the container would increase rapidly, putting pressure on the engineering teams to **keep ahead of exploits and vulnerabilities**.
|
||
|
|
1. **The security attack surface within the container would be greatly increased** with each new dependency. These containers include secrets which, if leaked via an exploit would need costly application-wide secret rotation to be done.
|
||
|
|
1. **Development velocity will be negatively impacted** as engineers work to avoid dependency conflicts between libraries.
|
||
|
|
1. Additionally there may be **extra complexity due to different hardware requirements** for different libraries with appropriate drivers etc for GPUs, TPUs, CUDA versions, etc.
|
||
|
|
1. Our Kubernetes workloads have been tuned for the existing multithreaded Ruby request (Rails) and message (Sidekiq) processes. Adding extremely resource-intensive applications into these workloads would affect unrelated requests, **starving requests of CPU and memory and requiring complex tuning to ensure fairness**. Failure to do this would impact our availability of GitLab.com.
|
||
|
|
|
||
|
|
|
||
|
|
\
|
||
|
|
[source](https://docs.google.com/drawings/d/1aYffBzzea5QuZ-mTMteowefbV7VmsOuq2v4BqbPd6KE/edit)
|
||
|
|
|
||
|
|
### Proposal: Avoid Overfilling GitLabs Application Containers with Service-Integration
|
||
|
|
|
||
|
|
GitLab.com migrated to Kubernetes several years back, but for numerous good reasons, the application architecture deployed for GitLab.com remains fairly simple.
|
||
|
|
|
||
|
|
Instead of embedding these applications directly into the Rails and/or Sidekiq containers, we run them as small, independent Kubernetes deployments, isolated from the main workload.
|
||
|
|
|
||
|
|
\
|
||
|
|
[source](https://docs.google.com/drawings/d/1ZPprcSYH5Oqp8T46I0p1Hhr-GD55iREDvFWcpQq9dTQ/edit)
|
||
|
|
|
||
|
|
The service-integration approach has already been used for the [Suggested Reviewers feature](https://gitlab.com/gitlab-com/gl-infra/readiness/-/merge_requests/114) that has been deployed to GitLab.com.
|
||
|
|
|
||
|
|
This approach would have many advantages:
|
||
|
|
|
||
|
|
1. **Componentization and Replaceability**: some of these AI feature experiments will likely be short-lived. Being able to shut them down (possibly quickly, in an emergency, such as a security breach) is important. If they are terminated, they are less likely to leave technical debt behind in our main application workloads.
|
||
|
|
1. **Security Isolation**: experimental services can run with access to a minimal set of secrets, or possibly none. Ideally, the services would be stateless, with data being passed in, processed, and returned to the caller without access to PostgreSQL or other data sources. In the event of a remote code exploit or other security breach, the attacker would have limited access to sensitive data.
|
||
|
|
1. In lieu of direct access to the main or CI Postgres clusters, services would be provided with access to the internal GitLab API through a predefined internal URL. The platform should provide instrumentation and monitoring on this address.
|
||
|
|
1. In future iterations, but out of scope for the initial delivery, the platform could facilitate automatic authentication against the internal API, for example by managing and injecting short-lived API tokens into internal API calls, or OIDC etc.
|
||
|
|
1. **Resource Isolation**: resource-intensive workloads would be isolated to individual containers. OOM failures would not impact requests outside of the experiment. CPU saturation would not slow down unrelated requests.
|
||
|
|
1. **Dependency Isolation**: different AI libraries will have conflicting dependencies. This will not be an issue if they're run as separate services in Kubernetes.
|
||
|
|
1. **Container Size**: the size of the main application containers is not drastically increased, placing a burden on the application.
|
||
|
|
1. **Distribution Team Bottleneck**: The Distribution team avoids becoming a bottleneck as demands for many different libraries to be included in the main application containers increase.
|
||
|
|
1. **Stronger Ownership of Workloads**: teams can better understand how their workloads are running as they run in isolation.
|
||
|
|
|
||
|
|
However, there are several outstanding questions:
|
||
|
|
|
||
|
|
1. **Availability Requirements**: would experimental services have the same availability requirements (and alerting requirements) as the main application?
|
||
|
|
1. **Oncall**: would teams be responsible for handling pager alerts for their services?
|
||
|
|
1. **Support for non-SAAS GitLab instances**: initially all experiments would target GitLab.com, but eventually we may need to consider how to support other instances.
|
||
|
|
1. There are three possible modes for services:
|
||
|
|
1. `M1`: GitLab.com only: only GitLab.com supports the service.
|
||
|
|
1. `M2`: SAAS-hosted for use with self-managed instance and instance-hosted: a singular SAAS-hosted service supports self-managed instances and GitLab.com. This is similar to the [GitLab Plus proposal](https://gitlab.com/groups/gitlab-org/-/epics/308).
|
||
|
|
1. `M3`: Instance-hosted: each instance has a copy of the service. GitLab.com has a copy for GitLab.com. Self-managed instances host their copy of the service. This is similar to the container registry or Gitaly today.
|
||
|
|
1. Initially, most experiments will probably be option 1 but may be promoted to 2 or 3 as they mature.
|
||
|
|
1. **Promotion Process**: ML/AI experimental features will need to be promoted to non-experimental status as they mature. A process for this will need to be established.
|
||
|
|
|
||
|
|
#### Proposed Guidelines for Building ML/AI Services
|
||
|
|
|
||
|
|
1. Avoid adding any large ML/AI libraries needed to support experimentation to the main application.
|
||
|
|
1. Create an platform to support individual ML/AI experiments.
|
||
|
|
1. Encourage supporting services to be stateless (excluding deployed models and other resources generated during ML training).
|
||
|
|
1. ML/AI experiment support services must not access main application datastores, including but not limited to main PostgreSQL, CI PostgreSQL, and main application Redis instances.
|
||
|
|
1. In the main application, client code for services should reside behind a feature-flag toggle, for fine-grained control of the feature.
|
||
|
|
|
||
|
|
#### Technical Details
|
||
|
|
|
||
|
|
Some points, in greater detail:
|
||
|
|
|
||
|
|
##### Traffic Access
|
||
|
|
|
||
|
|
1. Ideally these services should not be exposed externally to Internet traffic: only internally to our existing Rails and Sidekiq workloads should be routed.
|
||
|
|
1. For services intended to run at `M2`: "SAAS-hosted for use with self-managed instance and instance-hosted", we would expect to migrate the service to a public endpoint once sufficient security review has been performed.
|
||
|
|
|
||
|
|
##### Platform Requirements
|
||
|
|
|
||
|
|
In order to quickly deploy and manage experiments, an minimally viable platform will need to be provided to stage-group teams. The technical implementation details of this platform are out of scope for this blueprint and will require their own blueprint (to follow).
|
||
|
|
|
||
|
|
However, Service-Integration will establish certain necessary and optional requirements that the platform will need to satisfy.
|
||
|
|
|
||
|
|
###### Ease of Use, Ownership Requirements
|
||
|
|
|
||
|
|
1. <a name="R100">`R100`</a>: Required: the platform should be easy to use: imagine Heroku with [GitLab Production Readiness-approved](https://about.gitlab.com/handbook/engineering/infrastructure/production/readiness/) defaults.
|
||
|
|
1. <a name="R110">`R110`</a>: Required: with the exception of an Infrastructure-led onboarding process, services are owned, deployed and managed by stage-group teams. In other words,services follow a "You Build It, You Run It" model of ownership.
|
||
|
|
1. <a name="R120">`R120`</a>: Required: programming-language agnostic: no requirements for services. Services should be packaged as container images.
|
||
|
|
1. <a name="R130">`R130`</a>: Recommended: Each service should be evaluated against the GitLab.com [Service Maturity Model](https://about.gitlab.com/handbook/engineering/infrastructure/service-maturity-model/).
|
||
|
|
1. <a name="R140">`R140`</a>: Recommended: services using the platform have expedited production-readiness processes.
|
||
|
|
1. Production-readiness requirements graded by service maturity: low-traffic, low-maturity experimental services will have lower requirement thresholds than more mature services.
|
||
|
|
1. By default, the platform should provide services with defaults that would pass production-readiness review for the lowest service maturity-level.
|
||
|
|
1. At introduction, lowest maturity services can be deployed without production readiness, provided the meet certain automatically validated requirements. This removes Infrastructure gate-keeping from being a blocker to experimental service delivery.
|
||
|
|
|
||
|
|
###### Observability Requirements
|
||
|
|
|
||
|
|
1. <a name="R200">`R200`</a>: Required: the platform must provide SLIs for services out-of-the-box.
|
||
|
|
1. While it is recommended that services expose internal metrics, it is not mandatory. The platform will provide monitoring from the load-balancer. This is to speed up deployment by removing barriers to experimentation.
|
||
|
|
1. For services that provide internal metrics scrape endpoints, the platform must be configurable to collect these.
|
||
|
|
1. The platform must provide generic load-balancer level SLIs for all services. Service owners must be able to select from constructing SLIs from internal application metrics, the platform-provided external SLIs, or a combination of both.
|
||
|
|
1. <a name="R210">`R210`</a>: Required: Observability dashboards, rules, alerts (with per-term routing) must be generated from a manifest.
|
||
|
|
1. <a name="R220">`R220`</a>:Required: standardized logging infrastructure.
|
||
|
|
1. Mandate that all logging emitted from services must be Structured JSON. Text logs are permitted but not recommended.
|
||
|
|
1. See [Common Service Libraries](#common-service-libraries) for more details of building common SDKs for observability.
|
||
|
|
|
||
|
|
###### Deployment Requirements
|
||
|
|
|
||
|
|
1. <a name="R300">`R300`</a>: Required: No secrets stored in CI/CD.
|
||
|
|
1. Authentication with Cloud Provider Resources should be exclusively via OIDC, managed as part of the platform.
|
||
|
|
1. Secrets should be stored in the Infrastructure-provided Hashicorp Vault for the environment and passed to applications through files or environment variables.
|
||
|
|
1. Generation and management of service account tokens should be done declaratively, without manual interaction.
|
||
|
|
1. <a name="R310">`R310`</a>: Required: multiple environment should be supported, eg Staging and Production.
|
||
|
|
1. <a name="R320">`R320`</a>: Required: the platform should be cost-effective. Kubernetes clusters should support multiple services and teams.
|
||
|
|
1. <a name="R330">`R330`</a>: Recommended: gradual rollouts, rollbacks, blue-green deployments.
|
||
|
|
1. <a name="R340">`R340`</a>: Required: services should be isolated from one another.
|
||
|
|
1. <a name="R350">`R350`</a>: Recommended: services should have the ability to specify node characteristic requirements (eg, GPU).
|
||
|
|
1. <a name="R360">`R360`</a>: Required: Developers should not need knowledge of Helm, Kubernetes, Prometheus in order to deploy. All required values are configured and validated in project-hosted manifest before generating Kubernetes manifests, Prometheus rules, etc.
|
||
|
|
1. <a name="R370">`R370`</a>: Initially services should be synchronous only - using REST or GRPC requests.
|
||
|
|
1. This does not however preclude long-running HTTP(s) requests, for example long-polling or Websocket requests.
|
||
|
|
1. <a name="R390">`R390`</a>: Each service hosted in its own GitLab repository with deployment manifest stored in the repository.
|
||
|
|
1. Continuous deployments that are initiated from the CI pipeline of the corresponding GitLab repository.
|
||
|
|
|
||
|
|
##### Security Requirements
|
||
|
|
|
||
|
|
1. <a name="R400">`R400`</a>: stateful services deployed on the platform that utilize their own stateful storage (for example, custom deployed Postgres instance), must not store application security tokens, cloud-provider service keys or other long-lived security tokens in their stateful stores.
|
||
|
|
1. <a name="R410">`R410`</a>: long-lived shared secrets are discouraged, and should be referenced in the service manifest as such, to allow for accounting and monitoring.
|
||
|
|
1. <a name="R420">`R420`</a>: services using long-lived shared secrets should ensure that secret rotation can take place without downtime.
|
||
|
|
1. During a rotation, old and new generations of secrets should pass authentication, allowing gradual roll-out of new secrets.
|
||
|
|
|
||
|
|
##### Common Service Libraries
|
||
|
|
|
||
|
|
1. <a name="R500">`R500`</a>: Experimental services would be strongly encouraged to adopt and use [LabKit](https://gitlab.com/gitlab-org/labkit) (for Go services), or [LabKit-Ruby](https://gitlab.com/gitlab-org/ruby/gems/labkit-ruby) for observability, context, correlation, FIPs verification, etc.
|
||
|
|
1. At present, there is no LabKit-Python library, but some experiments will run in Python, so building a library to providing observability, context, correlation services in Python will be required.
|